【论文精读】Hierarchical Attention Networks for Document Classification

关键词
- Attention: 注意力机制,用于提取一个向量的上下文表示,详情可参考:层层剖析,让你彻底搞懂Self-Attention的机制和原理
- 文档:一篇文章,包含多个句子
- 文档表示:一个向量,该向量表示该文档,即将文档映射成一个向量。
所需前置知识
- RNN与GRU
- Attention
- Word Embedding
论文核心内容总结
论文核心内容:该论文提出了一个模型(Hierarchical Attention Network),该模型是用来将一个文档表示成一个向量,以便输入到其他模型中进行预测
模型基本思路:一个文档是由多个句子组成,一个句子是由多个单词组成,所以按层进行拆解,先以单词为维度,将所有单词向量化后,然后通过注意力机制对单词的重要性进行评分,最后单词加权合并成句子向量,同理,再将句子向量通过注意力机制进行重要性评分,最终将句子加权合并成文档向量
模型架构如图所示:
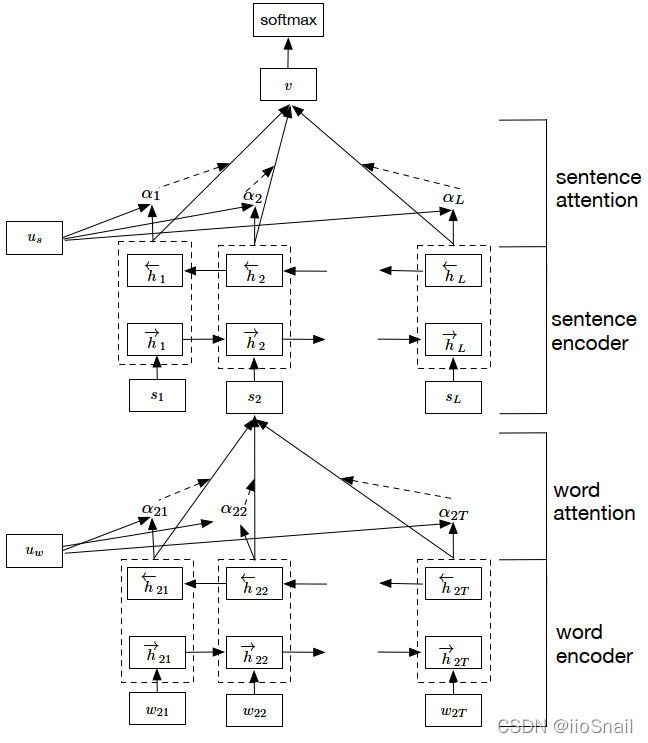
论文内容
接下来将会按照论文的顺序,总结论文中的关键内容
摘要
该模型具有两个特点:
- 它的层次结构可以反应文档的层次结构
- 它有两层Attention机制,分别用在word和sentence上,可以使得在构造文档表示时,可以提取word的上下文和sentence的上下文
简介
该模型基于了这个假设:一个文档中,不是所有的句子与问题相关,所以要对单词进行建模,提取它们的相关性,而不是把所有的单词孤立的看待。
该论文提出了一个新的神经网络架构,Hierarchical Attention Network (HAN),该架构捕捉了文档架构的两个基本要点:
- 文档是一个层次结构(文档由句子组成,而句子由词组成),所以作者按照这个思路,先构建“句子表示”,然后再将多个句子表示合并成“文档表示”。
- 不同的单词和句子对要回答的问题提供的信息量是不同的,除此之外,同样的单词或句子,出现在不同的位置,它们提供的信息量也可能不同,所以单词和句子的重要性是高度依赖上下文的
为了覆盖上述两个要点,所以提出了如图所示的架构:
Hierarchical Attention Networks详细介绍
该模型包含四个部分:
- word sequence encoder:用于将单词编码成向量
- word-level attention layer: 用于提取单词的上下文信息
- sentence encoder:用于将单词向量合并成句子向量
- sentence-level attention layer:用于提取句子的上下文信息
下面介绍细节
基于GRU的Sequence Encoder
这里介绍了以下GRU(RNN的一种),建议去其他地方学。可以参考:人人都能看懂的GRU
这里我将作者的内容复述一遍:
GRU使用了一个门控机制(gating mechanism)来跟踪序列状态,它并不像LSTM那样使用分离的记忆单元(Memory Cell)来保存长短记忆。其包含两个门:
- 重置门(reset gate) $r_t$ :控制着应该有多少历史信息应该被保留下来,如果 $r_t$ 全是0,意味着要遗忘所有的历史信息
- 更新门(update gate) $z_t$ : 决定有多少过去的信息应该被保留下来,有多少当前的信息应该被添加进来
它们同时控制信息应该如何被更新到隐状态中,在 $t$ 时刻,GRU计算新的隐状态的公式为:
$$ \begin{aligned} h_t = \left(1-z_{t}\right) \odot h_{t-1}+z_{t} \odot \tilde{h}_{t} ~~~~~~~~~~~~(1) \end{aligned} $$
该公式包含的几个符号为:
- $h_{t-1}$:上一时刻的隐状态
- $\odot$:两向量对应元素相乘(element-wise)
- $\tilde{h}_{t}$:$t$ 时刻的隐状态,类似传统RNN方式计算出的 $h_t$
通过公式(1),可以看出 $z_t$的作用为: $z_t$ 决定有多少过去的信息应该被保留下来,有多少当前的信息应该被添加进来。例如,如果 $z_t$ 中的元素都接近于0,那么 $(1-z_t)$ 就都接近于1,也就是说,将之前时刻的信息都保存下来,本时刻的信息基本都不要。
而 $z_t$ 的计算公式如下:
$$ \begin{aligned} z_{t}=\sigma\left(W_{z} x_{t}+U_{z} h_{t-1}+b_{z}\right) \end{aligned} $$
其中:
- $x_t$:$t$ 时刻的输入
- $\sigma$ :为sigmoid函数
- $W_z,U_z, b_z$:需要训练的矩阵和偏置,可以使用线性层进行训练
$\tilde{h_t}$ 的计算与传统RNN类似,公式如下:
$$ \begin{aligned} \tilde{h}_{t}=\tanh \left(W_{h} x_{t}+r_{t} \odot\left(U_{h} h_{t-1}\right)+b_{h}\right) \end{aligned} $$
其中:
- $x_t$:$t$ 时刻的输入
- $r_t$:重置门
- $W_h, U_h, b_h$:需要训练的矩阵和偏置,可以使用线性层进行训练
重置门 $r_t$ 控制着应该有多少历史信息应该被保留下来,如果 $r_t$ 全是0,意味着要遗忘所有的历史信息。$r_t$ 的计算公式如下:
$$ \begin{aligned} r_{t}=\sigma\left(W_{r} x_{t}+U_{r} h_{t-1}+b_{r}\right) \end{aligned} $$
其中:
- $W_r, U_r, b_r$:需要训练的矩阵和偏置,可以使用线性层进行训练
Hierarchical Attention介绍
首先,熟悉几个作者定义的符号:
- $L$:文档中句子的数量
- $s_i$:文档中的第 $i$ 个句子(sentence)
- $T_i$:第 $i$ 个句子的单词数量
- $w_{it}$: 第 $i$ 个句子的第 $t$ 个单词
接下来会对网络架构的每一层进行详细说明:
Word Encoder:将单词进行编码,经过如下步骤:
- 首先将单词 $w_{it}$ 通过一个矩阵 $W_e$ (例如,Word2Vec)将其编码成 $x_{it}$,公式如下:$$\begin{aligned}x_{it}=W_ew_{it} ~~~~t\in [1,T]\end{aligned}$$ $t\in [1,T]$ 表示 $t$ 从 $1$到 $T$
- 使用双向GRU来获得各方向包含上下文的单词向量表示,公式如下:$$ \begin{aligned} &\overrightarrow{h}_{i t}=\overrightarrow{\operatorname{GRU}}\left(x_{i t}\right), t \in[1, T] \\ &\overleftarrow{h}_{i t}=\overleftrightarrow{\operatorname{GRU}}\left(x_{i t}\right), t \in[T, 1] \end{aligned} $$
- 将$\overrightarrow{h}_{i t}$ 和 $\overleftarrow{h}_{i t}$ 合并为 $h_{it}$,例如,可以直接拼接起来,$h_{it} = [\overrightarrow{h}_{i t}, \overleftarrow{h}_{i t}]$
如果向量 $\overleftarrow{h}_{i t}$ 和 $\overrightarrow{h}_{i t}$ 的维度都为50,则 $h_{it}$ 的维度为100
总结:Word Encoder是利用双向GRU,将输入向量 $w_{it}$ 转化为向量 $h_{it}$,其中 $h_{it}$ 包含了 $i$ 句子的所有上下文信息
Word Attention:不是所有单词对理解句子的贡献都是相等的。因此,作者引入了Attention机制来提取“哪些单词对理解句子的更重要”,然后将单词向量加权求和,合并成一个句子向量,公式如下:
$$ \begin{aligned} u_{i t} &=\tanh \left(W_{w} h_{i t}+b_{w}\right) \\\\ \alpha_{i t} &=\frac{\exp \left(u_{i t}^{\top} u_{w}\right)}{\sum_{t} \exp \left(u_{i t}^{\top} u_{w}\right)} \\\\ s_{i} &=\sum \alpha_{i t} h_{i t} \end{aligned} $$
公式解释如下:
- 作者首先让 $h_{it}$ 过个一层的感知机(MLP),得到 $u_{it}$, 这里的 $W_{w}$ 和 $b_w$ 是需要训练的矩阵,可以使用线性层训练。
- $u_{it}$ 与查询向量 $u_w$ 做内积,求出 $u_{it}$ 的重要程度 $\alpha_{it}$,并将经过softmax进行归一化,其中查询向量 $u_w$ 是训练出来的
- 最终对 $h_{it}$ 进行加权求和,得出句子的向量表示 $s_i$
总结:该步骤通过Attention机制,获取每个 $h_{it}$ 的重要程度权重后,对 $h_{it}$ 进行加权求和,得到句子的向量表示 $s_i$
Sentence Encoder: 与Word Encoder同理,公式如下:
$$ \begin{aligned} &\overrightarrow{h}_{i}=\overrightarrow{\mathrm{GRU}}\left(s_{i}\right),~~~ i \in[1, L] \\\\ &\overleftarrow{h}_{i}=\overleftrightarrow{\mathrm{GRU}}\left(s_{i}\right),~~~~ i \in[L, 1] \\\\ & h_i = [\overrightarrow{h}_{i}, \overleftarrow{h}_{i}] \end{aligned} $$
Sentence Attention:与Word Attention同理,最终得到文档的向量表示 $v$,公式如下:
$$ \begin{aligned} u_{i} &=\tanh \left(W_{s} h_{i}+b_{s}\right) \\\\ \alpha_{i} &=\frac{\exp \left(u_{i}^{\top} u_{s}\right)}{\sum_{i} \exp \left(u_{i}^{\top} u_{s}\right)} \\\\ v &=\sum_{i} \alpha_{i} h_{i} \end{aligned} $$
到这里,作者提出的架构已经讲完了
文档分类
当得到了文档表示 $v$ ,然后就可以将其丢到其他的神经网络中进行分类了。作者采用的是一层前馈神经网络,输出层使用的softmax进行归一化,公式为:
$$ \begin{aligned} p = \text{softmax}(W_c v +b_c) \end{aligned} $$
作者使用的激活函数为NLLLOSS(Negative Log Likelihood),公式为:
$$ \begin{aligned} L = - \sum_d \log p_{dj} \end{aligned} $$
其中:
- $d$: 代表文档(document)
- $j$: 文档对应的类别
实验部分
数据集
作者用六个大数据集做了实验,数据集分两种:情感分类(Sentiment Estimation) 和 主题分类(Topic Classification)
作者将数据集拆分为:80%训练集,10%验证集,10%测试集
作者使用的数据集如下:
-
Yelp reviews 2013,2014,2015: 数据集地址 ,
网盘链接:https://pan.baidu.com/s/18CR0JAT_OnS0z4jgysfsZA 提取码:etbj -
IMDB reviews
- Yahoo answers
- Amazon reviews
模型配置和训练
作者使用的模型参数如下:
- 分句和分词:作者使用的是Standford's CoreNLP进行的分词和分句
- 异常单词:作者将出现次数大于5的单词作为正常单词,小于等于5单词的单词直接使用
UNK替换 - Word Embedding: 作者使用的是自主训练的Word2Vec,训练集和验证集是分开训练的,该模型就对应第一个公式的 $W_e$
- 维度: word embedding 维度为 200,GRU维度为50,这样双向GRU后的 $h_{it}$ 的维度就是100,那么,句子向量 $s_i$ 的维度也是100
- batch_size: 64
- 文档长度:作者将文档文档的句子数量固定(即每个文档的句子数一样),因为作者发现这样可以比正常快3倍
- 梯度下降:作者使用的是随机梯度下降法(Stochastic Gradient Descent),momentum设置为 $0.9$
- 学习率:作者通过在验证集上进行网格搜索(grid search) 找了一个最好的想学习率,但没具体说是多少
实验结果与分析
总结:在各数据集上的表现都比其他数据集好
Context dependent attention weights(分析)
作者说明了它的模型可以通过单词的上下文捕获到该单词在注意力机制中应该占得权重。
问题分析:同一个单词在不同的上下文中,注意力占比不一定相同,例如,评论中出现good不一定就说明这是个好评,有可能评论者只想说明只是部分好,也有可能前面还有个 not
作者表明,它的模型可以解决上述问题,作者给出了good单词在不同评分下的注意力权重分布,如图所示:
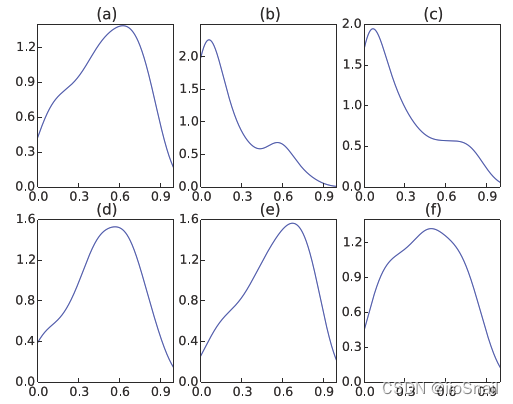
上图中图(a)为(b-f)的整合。图(b)-图(e)表示1星到5星评分下,good单词的注意力权重分布。可以看出,1星时,good占比很低,说明good在1星的评论里面,这个单词不太重要,而随着星级的提高,good的注意力占比越来越高。说明HAN架构确实能根据单词上下文判断出它的重要程度。
结论
作者提出了一个 Hierarchical Attention Network(HAN) 模型,该模型利用Attention机制,将单词向量合并成句子向量,再将句子向量合并成文档向量,最终使用该模型可以得到一个文档的向量表示,然后再将该文档表示输入到下游任务,可以得到很好地表现。
参考资料
Hierarchical Attention Networks for Document Classification: https://aclanthology.org/N16-1174.pdf
层层剖析,让你彻底搞懂Self-Attention的机制和原理:https://blog.csdn.net/zhaohongfei_358/article/details/122861751
gensim 快速入门 Word2Vec:https://blog.csdn.net/zhaohongfei_358/article/details/121695219



