Redis Ops Guide - Quick Interview Notes (Crash Course)

Table of Content
1. Redis Persistence
To minimize data loss in Redis, persistence mechanisms are used to save data to disk.
Redis provides two persistence options:
- Snapshotting (RDB): This method involves saving the entire dataset to disk at a specific point in time, creating an RDB file.
- Advantages: ① Fast data recovery; ② High storage efficiency. ③ Suitable for backups. ④ Backup files are compact and use minimal storage space.
- Disadvantages: ① Some data may be lost. ② Resource-intensive during backups. ③ Compatibility issues between different Redis versions.
- Append-Only File (AOF): Each write command is logged to disk in real-time or at intervals.
- Advantages: Minimal or no data loss (depending on configuration).
- Disadvantages: ① Slower data recovery, as it replays all logged commands. ② Frequent disk writes. ③ Larger file sizes compared to RDB.
Both methods can be used together. When Redis starts, it prioritizes AOF for data recovery if both options are enabled.
1.1 Snapshotting (RDB)
There are several ways to create RDB snapshots:
- Execute the
savecommand: While fast, this command blocks other operations, making it unsuitable for production environments. - Execute the
bgsavecommand:bgsaveruns in the background using a child process, avoiding disruption to normal operations. - Configure
save <seconds> <changes>: This triggers abgsavecommand automatically when the specified number of write operations (<changes>) occurs within a time window (<seconds>). Multiple configurations are possible, for example: save 60 10000: Triggersbgsaveif 10,000 writes occur within 60 seconds.save 300 10: Triggersbgsaveif 10 writes occur within 300 seconds.save 900 1: As a fallback, ensuresbgsaveexecutes if at least one write occurs within 900 seconds.
Key considerations for BGSAVE:
bgsavecreates a child process and copies the in-memory data to persist it on disk. For this reason, the master node should use no more than 50% of available memory to avoid memory overflow during the process.
Important Notes for RDB:
- High memory usage by bgsave: During
bgsave, the current data is copied before being dumped to disk, requiring at least 50% additional memory. - Forking overhead:
bgsaveinitiates a fork operation to create a child process, which is single-threaded and may delay other commands in the queue. - Potential data loss: If only RDB is used for persistence, any data written between the last backup and a system crash will be lost.
1.2 AOF Mode
Configuring AOF: To enable AOF, modify the redis.conf configuration file as follows:
``` # Enable AOF appendonly yes # Set the synchronization policy: always, everysec, or no appendfsync everysec ```
Three AOF Persistence Policies:
- always:Writes each command to the disk immediately after it's executed. This minimizes data loss (at most one command might be lost). However, there are risks:
- If writes are frequent, the disk's write speed might not keep up with memory operations.
- For SSDs, frequent writes can significantly reduce their lifespan.
- everysec(Recommended): Writes data to disk every second. This achieves a good balance between minimizing data loss (at most one second) and reducing the frequency of disk writes.
- no: Leaves the decision to the operating system, typically syncing data every 30 seconds. This option is not recommended, as it defeats the purpose of using AOF for reliability.
Important Considerations for AOF:
- High Disk Usage: Since AOF logs every write operation, it can consume a large amount of disk space. Regularly monitor disk capacity to avoid running into issues.
- Long Recovery Time:During recovery, AOF replays every write operation sequentially. If AOF is the only backup method, Redis restarts after a crash can take a long time.
- AOF Rewrite Mechanism:AOF includes a rewrite feature to periodically optimize the log file size by consolidating commands (e.g., only keeping the latest write operation for a frequently updated key). However, this process can consume significant CPU and I/O resources while it’s running.
2. Redis Master-Slave Model (High Availability)
Redis can achieve high availability through its master-slave replication model. In this setup, a single Redis master node can have multiple slave nodes. The master node handles both read and write operations, while the slave nodes are responsible for backing up the master's data. (Optionally, the master-slave model can also support read-write separation, where read operations are performed on slave nodes. However, this may introduce latency.)
When the master node goes down, Redis can automatically promote one of the slave nodes to become the new master node. This ensures high availability, as long as the master and all slaves do not fail simultaneously.
2.1 Redis Master-Slave Replication
To ensure data consistency between the master and slave nodes, Redis performs master-slave replication, which synchronizes data from the master to the slaves.
There are two types of synchronization:
- Full synchronization: Copies all the master's data to the slave node.
- Trigger scenarios: Full synchronization occurs when the data gap between the master and slave nodes is too large. Common cases include: ① The slave node connects to the master node for the first time. ② The slave node has been offline for an extended period and reconnects to the master.
- How it works: When a slave connects to the master, it reports its replication offset (i.e., the last position it synced). The master checks if the required data is still available in its buffer. If not, full synchronization is triggered; otherwise, partial synchronization occurs.
- Method: Full synchronization is performed using the RDB snapshot method. The master generates an RDB file and sends it to the slave node. Once the full sync is complete, incremental updates are handled via partial synchronization.
- Partial synchronization: Syncs only recent updates from the master to the slave node.
- How it works: When the master node processes write commands, it appends these commands to a replication backlog buffer. The master sends the buffered commands to the slave nodes either when the buffer is full or during periodic updates.
Detailed Synchronization Process When a Slave Node First Connects and Reconnects to the Master Node:
| Step | Master Node | Slave Node |
|---|---|---|
| 1 | Waits for the slave node to connect | |
| 2 | Sends the SYNC command to connect to the master node | |
| 3 | Performs a BGSAVE operation.During this process, any new commands received from clients are logged in a buffer. |
|
| 4 | Once BGSAVE is complete, sends the RDB file to the slave node. |
|
| 5 | After receiving the RDB file, discards its current data and loads the RDB file sent by the master node. | |
| 6 | Sends the buffered commands to the slave node. | |
| 7 | Applies the buffered commands received from the master node. | |
| 8 | All buffered commands are sent. | |
| 9 | Receives a new write command and synchronizes it to the slave node. | |
| 10 | Executes the write command received from the master node. | |
| 11 | Steps 9 and 10 repeat continuously. |
Note: If a slave node goes offline for a short period and reconnects, it will inform the master node of the last replication offset. If the master node's buffer contains the data corresponding to this offset, partial synchronization will occur. Otherwise, a full synchronization will be initiated.
Common Configuration Options for Master-Slave Replication:
- slave-read-only=yes:Determines whether the slave node is read-only. Typically set to yes, as writes to the master node cannot be synchronized to any other node.
- repl-disable-tcp-nodelay:Controls synchronization latency for master-slave communication. By default, this is disabled, meaning every command is synchronized immediately, resulting in low latency but higher bandwidth usage. When enabled, the master node combines multiple commands into batches before sending them, reducing bandwidth usage but increasing latency (approximately 40 ms). If the slave node is only used for disaster recovery (not for read/write splitting) and the network bandwidth is constrained, enabling this option is recommended.
- repl-backlog-size:Defines the size of the replication backlog buffer used for syncing data to slave nodes. If the data to be synchronized exceeds this buffer size, a full synchronization will be triggered. The default size is 1 MB, but increasing it to 100 MB is recommended to avoid frequent full synchronizations.
2.2 Redis Topologies
Redis master-slave replication can generally be designed in three common topologies: One master and one slave, one master and several salves, and hierarchical (tree-like) master-slave structure.
If there are multiple master nodes, the same principles apply. The following descriptions are based on the perspective of a single master node.
One master and one slave:A single master node with one slave node, typically used for disaster recovery.

Key Considerations:
- Avoid using "One master and one slave" for read-write separation, as both the master and the slave must remain operational, defeating the purpose of disaster recovery.
- You can enable AOF persistence only on the slave node to reduce the load on the master node. However, be cautious: if the master node restarts without persistence enabled, it may synchronize with the slave node, potentially wiping out the data, leading to data loss.
one master and several salves:A single master node with multiple slave nodes, often used to implement read-write separation.

Key Considerations:
- For scenarios with high read and low write workloads, read-write separation using "one master and several salves" can effectively reduce the load on the master node.
- If the workload involves both high read and high write operations or if there are too many slave nodes, it's recommended to switch to a hierarchical structure. This prevents excessive synchronization pressure on the master node.
- Be mindful of replication storms. When the master node restarts or multiple slave nodes attempt to reconnect simultaneously, they may all request full synchronization, creating significant bandwidth pressure on the master. A hierarchical structure can help mitigate this issue.
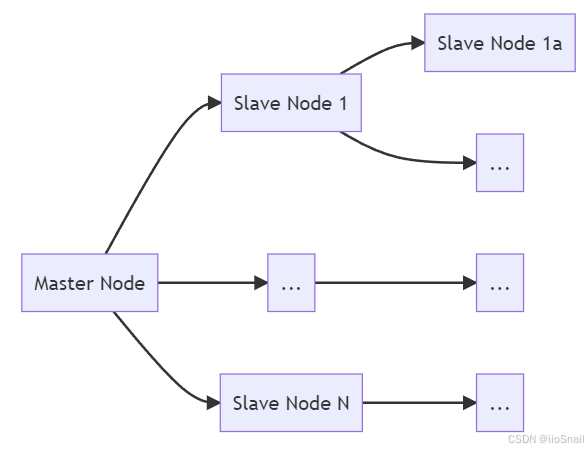
Hierarchical (Tree-Like) Master-Slave Structure:In this topology, the master node has slave nodes, and those slave nodes, in turn, have their own slave nodes. This structure is used to reduce the synchronization pressure on the master node, as downstream slaves replicate data from upstream slave nodes.
3. Redis Cluster (High Concurrency)
All write operations in Redis must be performed on the master node. If there is only one master node, achieving high concurrency is not feasible.
To address this limitation, Redis introduced a distributed solution known as Redis Cluster.
3.1 Slots in Redis
The high throughput of Redis is not only due to its in-memory design but also because it is based on a Hash algorithm.
Redis uses a hash space of 16,384 slots.
When performing operations on a key, Redis first computes which slot the key belongs to using the formula CRC16(key) % 16384 (where CRC16 is a type of hash algorithm). The key is then mapped to that slot for processing.
In a single master node setup, all slots are hosted on that single master node.
In a Redis Cluster (with multiple master nodes), slots are distributed evenly across different master nodes. For example:
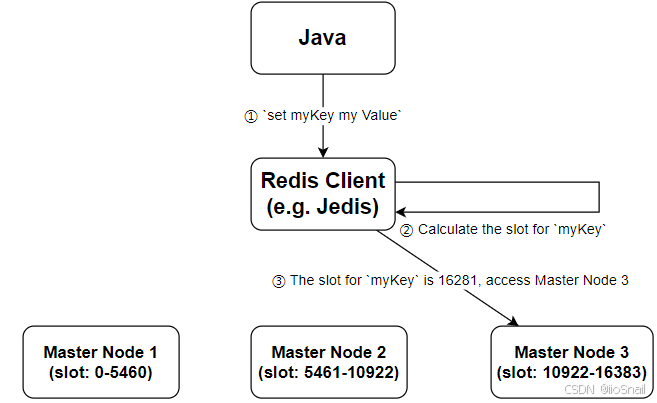
When a client connects to a Redis Cluster, it retrieves information about all nodes in the cluster. For any key operation, the client calculates the slot for the key and directly accesses the corresponding master node.
If the key’s slot is not on the accessed master node, an error of type "MOVED" is returned. For example:
(error) MOVED 16281 127.0.0.1:7003This indicates that the key belongs to slot 16281, which is not hosted on the current node. Instead, the client should access the node at127.0.0.1:7003.
3.2 Common Commands in Redis Cluster
You can use this project to quickly set up a Redis cluster for testing.
```python # View cluster information, including basic details, cluster status, slot status, etc. > cluster info # View node information, such as IP and port, master-slave relationships, slot ranges, etc. > cluster nodes # Calculate the slot to which a key belongs > cluster keyslot <your-key> ```
3.3 Multi-Master Multi-Slave Architecture
The Redis cluster distributes slots across multiple master nodes, reducing the write pressure on a single node and enabling high concurrency.
The master-slave architecture allows each master node to have multiple slave nodes. If a master node fails, it can automatically perform failover, achieving high availability.
Since Redis is inherently based on a hashing algorithm and an in-memory database, it provides high throughput and ensures high performance.
By combining these three features, you can build a Redis system with the "three highs": high concurrency, high availability, and high performance.
For example, a Redis architecture with three masters and six slave is shown below:
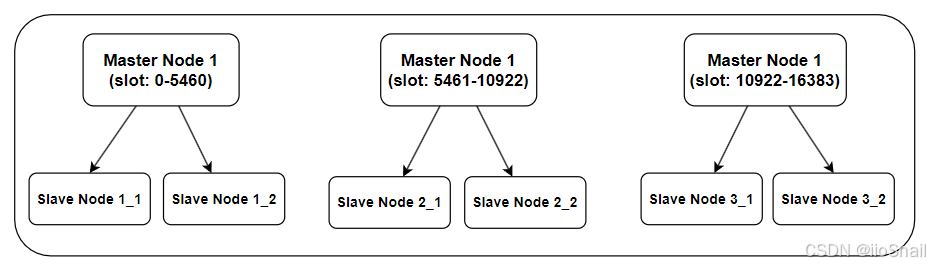
This setup includes three master nodes that equally share the slots. Each master node has two slave nodes for disaster recovery.
4. Redis Memory Management
4.1 Redis Memory Model
The memory usage in Redis can be divided into the following components:
- Data Object Memory: This refers to the memory consumed by the data stored by user.
- Program Memory:Memory required by Redis itself to run. This part is typically small.
- Buffer Memory:Redis utilizes three types of buffers:
- Client Buffers: Data read from or written to Redis by clients passes through read and write buffers. If there are many connected clients or large keys (BigKeys), buffer memory can overflow, leading to an out-of-memory (OOM) error.
- Replication Backlog Buffer:Used for synchronizing data with slave nodes. If a replica requests data that has already been removed from the buffer, a full synchronization will be triggered. It's recommended to set this buffer size to be relatively large.
- AOF Buffer: Temporarily stores recent write commands during AOF rewriting. The memory consumption here is usually minimal.
- Memory Fragmentation: To facilitate memory management, Redis uses an allocator that divides memory into fixed-size blocks. Each key is stored in a block that matches its size. However, the allocation is rarely exact, and some memory is wasted, referred to as memory fragmentation.
- Child Process Memory:(This could also be categorized under "Program Memory.") When performing
bgsaveor AOF rewriting, Redis spawns a child process that copies the parent process's data objects. This results in memory consumption roughly equivalent to the size of the data objects.
4.2 Checking Redis Memory Usage
You can use the info memory command to inspect Redis memory usage. Key metrics include:
- used_memory:The total memory usage, which includes "data object memory," "program memory," and "buffer memory."
- used_memory_human: A human-readable version of
used_memory. - used_memory_rss:The actual physical memory used by Redis, calculated as
used_memory + memory fragmentation. - used_memory_peak:The peak value of
used_memory. This helps administrators monitor maximum memory usage and ensure sufficient memory is available. - mem_fragmentation_ratio:The memory fragmentation ratio, calculated as
used_memory_rss / used_memory. A high ratio indicates severe fragmentation. Ifmem_fragmentation_ratio < 1, it suggests that memory swapping (use of virtual memory) has occurred, which requires attention.
4.3 Redis Memory Management and Optimization
Key configurations related to Redis memory management include:
- maxmemory:Specifies the maximum usable memory (excluding memory fragmentation). This can be modified dynamically. It’s important to reserve some memory for the operating system and Redis’s memory fragmentation to avoid running into OOM (Out Of Memory) errors.
- maxmemory-policy:Defines the memory eviction policy, which can also be configured dynamically. When memory usage reaches the maxmemory limit, Redis determines which keys to evict based on this policy. Common strategies include:
- noeviction:The default policy, where no data is evicted. Instead, Redis returns an OOM error to the client.
- volatile-lru:Evicts the least recently used (LRU) keys that have a set expiration time. If no eligible keys are found, it behaves like the noeviction policy.
- allkeys-lru:Evicts the least recently used keys regardless of whether they have an expiration time.
- volatile-ttl:Evicts keys that are closest to expiration. If no such keys exist, it falls back to the noeviction policy.
Common Redis Optimization Techniques:
- Shorten key lengths: Use shorter key names to reduce memory usage.
- Shorten value lengths:When Redis is used as an object cache, the following methods can help reduce the size of values: ① Remove unnecessary fields. ② Compress the JSON object before storing it. ③ Use serialization methods with higher compression ratios, such as
protostufforkryo. - Use integers whenever possible:Redis maintains an integer object pool for numbers in the range
[0-9999]. If your keys, values, or objects in lists and sets are integers, they can share these pre-allocated integer objects, reducing memory usage. Note: The integer object pool becomes ineffective if you use LRU-based policies like volatile-lru or allkeys-lru. This is because objects need to track their LRU values (i.e., the last access time), which prevents sharing. - Specify
ziplistas the underlying data structure: Forlist,hash, orzsettypes, you can configure Redis to useziplistas the underlying data structure. This approach can save memory but may reduce the efficiency of insert, update, and query operations—essentially trading time for space. (If you are not familiar with data structures, this option is generally not recommended.)
5. Common Redis Issues and Solutions
5.1 Out of Memory (OOM)
Redis may experience out-of-memory errors or sudden spikes in memory usage due to the following reasons:
- Large data volume: The issue arises when a substantial amount of data is being written into Redis.
- Ongoing
bgsaveoperation: When Redis executes abgsave, it creates a copy of the current memory, which significantly increases memory usage. A common symptom is that the memory usage on the master node is twice as much as on the slave node. - Buffer overflows: Redis uses buffers for interactions between the client and server during reads and writes. If the write/read operations are too fast or involve large keys (BigKeys), the buffers may overflow.
5.2 Command Blocking
Symptoms:
The client frequently experiences timeout errors.
Possible Causes:
- Slow queries: Since Redis is single-threaded, a slow query can block subsequent commands, causing the associated clients to time out. Common reasons for slow queries include inefficient use of APIs or data structures, such as running
keys *or operating on large objects. - CPU saturation: Redis commands run on a single CPU core. If that core becomes saturated, command execution will slow down or block. (Other cores handle background tasks such as I/O or replication.)
- Forking subprocesses: Operations like “RDB snapshots” and “AOF rewriting” involve forking a child process. Forking temporarily halts the main thread, and all commands must wait. The fork process can be particularly slow if Redis uses a large amount of memory, as the memory page table needs to be copied (e.g., 10GB of Redis memory typically requires 20MB of page table).
- AOF disk flushing delays: AOF persistence flushes data to disk once per second using
fsync. If the disk is under heavy load,fsyncmay take longer than expected. If the operation exceeds two seconds, Redis will pause all commands to ensure data safety until thefsyncis complete. - CPU contention: If Redis shares a server with other programs, the CPU may be overutilized, causing Redis to compete for processing power.
- Memory swapping: If the system runs out of RAM, some Redis data might be moved to virtual memory, drastically reducing read/write performance. It’s critical to monitor memory usage and disable swapping whenever possible.
- Network issues: Poor network conditions can lead to delays in command execution or client timeouts.


