层层剖析,让你彻底搞懂Self-Attention、MultiHead-Attention和Masked-Attention的机制和原理

Table of Content
本文内容
本文基于李宏毅老师对 Self-Attention 的讲解,进行理解和补充,并结合Pytorch代码,最终目的是使得自己和各位读者更好的理解Self-Attention
李宏毅Self-Attention链接: https://www.youtube.com/watch?v=hYdO9CscNes
PPT链接见视频下方
通过本文的阅读,你可以获得以下知识:
- 什么是Self-Attention,为什么要用Self-Attention
- Self-Attention是如何做的
- Self-Attention是如何设计的
- Self-Attention公式的细节
- MultiHead Attention
- Masked Attention
一、Self-Attention
1.1. 为什么要使用Self-Attention
假设现在一有个词性标注(POS Tags)的任务,例如:输入I saw a saw(我看到了一个锯子)这句话,目标是将每个单词的词性标注出来,最终输出为N, V, DET, N(名词、动词、定冠词、名词)。
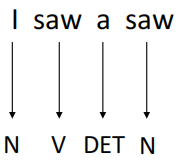
这句话中,第一个saw为动词,第二个saw(锯子)为名词。如果想做到这一点,就需要保证机器在看到一个向量(单词)时,要同时考虑其上下文,并且,要能判断出上下文中每一个元素应该考虑多少。例如,对于第一个saw,要更多的关注I,而第二个saw,就应该多关注a。
这个时候,就要Attention机制来提取这种关系:如果一个任务的输入是一个Sequence(一排向量),而且各向量之间有一定关系,那么就要利用Attention机制来提取这种关系。
1.2. 直观的感受下Self-Attention
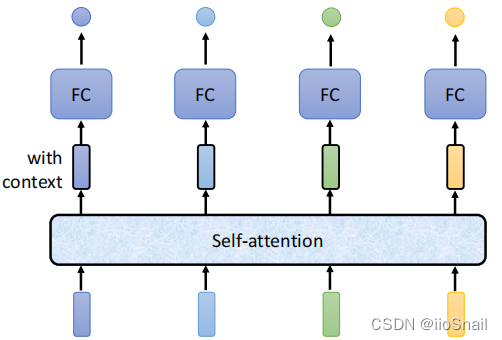
该图描述了Self-Attention的使用。Self-Attention接受一个Sequence(一排向量,可以是输入,也可以是前面隐层的输出),然后Self-Attention输出一个长度相同的Sequence,该Sequence的每个向量都充分考虑了上下文。 举个例子,输入是I、saw、a、saw,对应向量为:
$$ \begin{aligned} \text{I} = \begin{bmatrix} 1 \\ 0 \\ 0 \\ \end{bmatrix},~~\text{saw} = \begin{bmatrix} 0 \\ 1 \\ 0 \\ \end{bmatrix},~~\text{a} = \begin{bmatrix} 0 \\ 0 \\ 1 \\ \end{bmatrix},~~\text{saw} = \begin{bmatrix} 0 \\ 1 \\ 0 \\ \end{bmatrix} \end{aligned} $$
在经过Self-Attention层之后,可能就变成了这样:
$$ \begin{aligned} \text{I}' = \begin{bmatrix} 0.7 \\ 0.28 \\ 0.02 \\ \end{bmatrix},~~\text{saw}' = \begin{bmatrix} 0.34 \\ 0.65 \\ 0.01 \\ \end{bmatrix},~~\text{a}' = \begin{bmatrix} 0.2 \\ 0.2 \\ 0.6 \\ \end{bmatrix},~~\text{saw}' = \begin{bmatrix} 0.01 \\ 0.5 \\ 0.49 \\ \end{bmatrix} \end{aligned} $$
对于第一个saw,它除了自身外,还要考虑 $0.34$个I;对于第二个saw,它要考虑$0.49$个a。
1.3. Self-Attenion是如何考虑上下文的
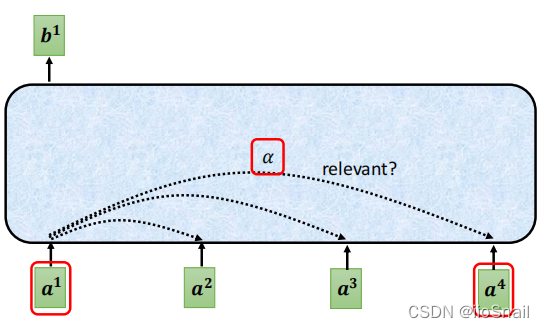
如图所示,每个输入都会和其他输入计算一个相关性分数,然后基于该分数,输出包含上下文信息的新向量。
对于上图,$a^1$需要与 $a^1,a^2,a^3,a^4$ 分别计算相关性分数 $\alpha_{1,1}, \alpha_{1,2}, \alpha_{1,3}, \alpha_{1,4}$(需要和自己也计算一下), $\alpha$ 的分数越高,表示两个向量的相关度越高。
计算好 $\alpha_{1,*}$ 后,就可以求出新的包含上下文信息的向量 $b^1$,假设 $\alpha_{1,1}=5, \alpha_{1,2}=2, \alpha_{1,3}=1, \alpha_{1,4}=2$,则:
$$ \begin{aligned} b_1 = \sum_{i}\alpha_{1,i} \cdot a^i = 5 \cdot a^1 + 2 \cdot a^2 + 1 \cdot a^3 + 2 \cdot a^4 \end{aligned} $$
同理,对于 $b_2$,首先计算权重 $\alpha_{2,1}, \alpha_{2,2}, \alpha_{2,3}, \alpha_{2,4}$ , 然后进行加权求和
如果按照上面这个式子做,还有两个问题:
- $\alpha$ 之和不为1,这样会将输入向量放大或缩小
- 直接用输入向量$a^i$去乘的话,拟合能力不够好
对于问题1,通常的做法是将 $\alpha$ 过一个Softmax(当然也可以选择其他的方式)
对于问题2,通常是将 $a^i$ 乘个矩阵(该矩阵是训练出来的),然后生成 $v^i$ ,然后用 $v^i$ 去乘 $\alpha$
1.4. 如何计算相关性分数 $\alpha$
首先,复习下向量相乘。两个向量相乘(做内积),公式为:$a \cdot b = |a||b| \cos \theta$ , 通过公式可以很容易得出结论:
- 两个向量夹角越小(越接近),其内积越大,相关性越高。反之,两个向量夹角越大,相关性越差,如果夹角为90°,两向量垂直,内积为0,无相关性
通过上面的结论,很容易想到,要计算 $a^1$ 和 $a^2$ 的相关性,直接做内积即可,即 $\alpha_{1,2} = a_1 \cdot a_2$ 。 但如果直接这样,显然不好,例如,句子I saw a saw的saw和saw相关性一定很高(两个一样的向量夹角为0),这样不就错了嘛。
为了解决上面这个问题,Self-Attention又额外“训练”了两个矩阵 $W^q$ 和 $W^k$
- $W^q$ 负责对“主角”进行线性变化,将其变换为 $q$,称为query,
- $W^k$ 负责对“配角”进行线性变化,将其变换为 $k$,称为key
有了$W^q和W^k$,我们就可以计算 $a^1$ 和 $a^2$ 的相关分数 $\alpha_{1,2}$了,即:
$$ \begin{aligned} \alpha_{1,2} = q^1 \cdot k^2 = (W^q \cdot a^1 )\cdot (W^k \cdot a^2) \end{aligned} $$
上面这些内容可以汇总成如下图:
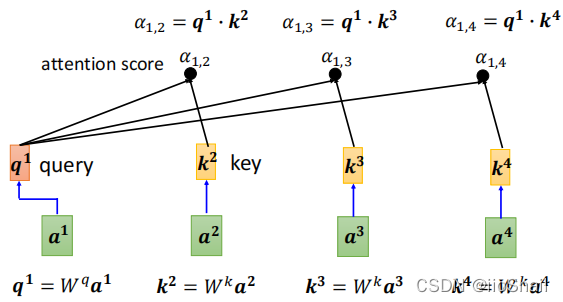
要计算 $a^1$(主角)与 $a^1, a^2, a^3, a^4$(配角)的相关度,需要经历如下几步:
- 通过 $W^q$ ,计算 $q^1$
- 通过 $W^k$,计算 $k^1, k^2, k^3, k^4$
- 通过 $q$ 和 $k$ , 计算 $\alpha_{1,1}, \alpha_{1,2}, \alpha_{1,3}, \alpha_{1,4}$
上图并没有把 $k^1$ 画出来,但实际计算的时候,需要计算 $k_1$,即需要计算 $a^1$和其自身的相关分数。
1.5. 将 $\alpha$ 归一化
还记得上面提到的,$\alpha$之和不为1,所以,在上面得到了 $\alpha_{1, *}$ 后,还需要过一下Softmax,将$\alpha_{1, *}$进行归一化。如下图:
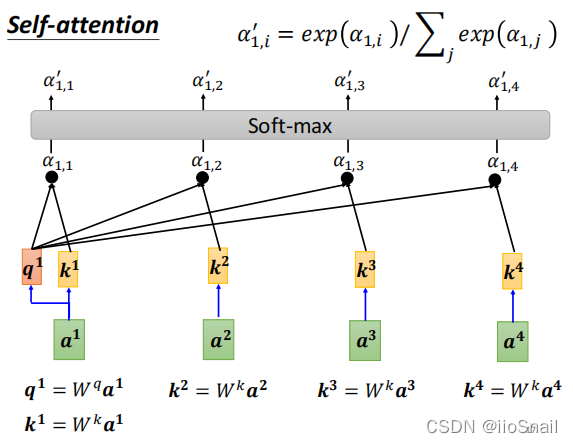
最终,会将归一化后的 $\alpha'_{1, *}$ 作为 $a^1$ 与其它向量的相关分数。 同理,$a^2, a^3, ...$ 向量与其他向量的相关分数也这么求。
不一定非要用Softmax,你开心想用什么都行,说不定效果还不错,也不一定非要归一化。 只是通常是这么做的
1.6. 整合上述内容
求出了相关分数 $\alpha '$,就可以进行加权求和计算出包含上下文信息的向量 $b$ 了。还记得上面提到过,如果直接用 $a$ 与 $\alpha '$ 进行加权求和,泛化性不够好,所以需要对 $a$ 进行线性变换,得到向量 $v$,所以Self-Attention还需要训练一个矩阵 $W^v$ 用于对 $a$ 进行线性变化,即:
$$ \begin{aligned} v^1 = W^v \cdot a^1 ~~~~~~~~v^2 = W^v \cdot a^2~~~~~~~~~v^3 = W^v \cdot a^3~~~~~~~~~~~v^4 = W^v \cdot a^4 \end{aligned} $$
然后就可用 $v$ 与 $\alpha '$ 进行加权求和,得到 $b$ 了。
$$ \begin{aligned} b^1 = \sum_i \alpha'_{1,i} \cdot v^i = \alpha'_{1,1} \cdot v^1 + \alpha'_{1,2} \cdot v^2 + \alpha'_{1,3} \cdot v^3 + \alpha'_{1,4} \cdot v^4 \end{aligned} $$
将求 $b^1$ 的整个过程可以归纳为下图:
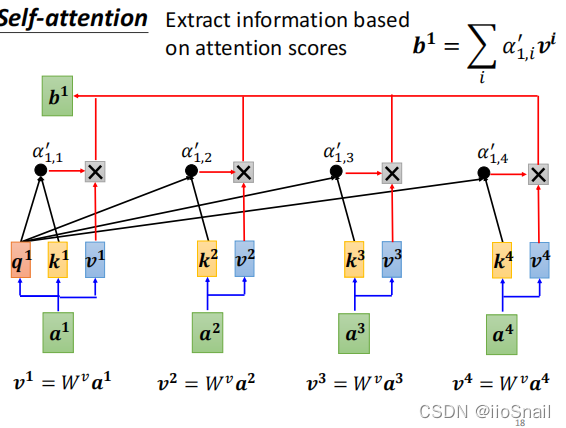
用更正式的话描述一下整个过程:
有一组输入序列 $I = (a^1, a^2, \cdots, a^n)$,其中 $a^i$ 为向量, 将序列 $I$ 通过Self-Attention,可以将其转化为另外一个序列 $O = (b^1, b^2, \cdots, b^n)$,其中向量 $b^i$ 是由向量 $a^i$ 结合其上下文得出的,$b^i$ 的求解过程如下:
- 求出查询向量 $q^i$, 公式为 $q^i = W^q \cdot a^i$
- 求出 $k^1,k^2, \cdots, k^n$,公式为 $k^j = W^k \cdot a^j$
- 求出 $\alpha_{i,1}, \alpha_{i,2}, \cdots, \alpha_{i,n}$ , 公式为 $\alpha_{i,j}=q^i\cdot k^j$
- 将 $\alpha_{i,1}, \alpha_{i,2}, \cdots, \alpha_{i,n}$ 进行归一化得到 $\alpha'_{i,1}, \alpha'_{i,2}, \cdots, \alpha'_{i,n}$,公式为 $\alpha'_{i,j} = \text{Softmax}(\alpha_{i,j};\alpha_{i,*}) = \exp(\alpha_{i,j})/\sum_t \exp(\alpha_{i,t})$
- 求出向量$v^1, v^2, \cdots, v^n$, 公式为: $v^j=W^v \cdot a^j$
- 求出 $b^i$, 公式为 $b^i = \sum_j \alpha'_{i,j} \cdot v^j$
其中,$W^q, W^k, W^v$ 都是训练出来的
到这里Self-Attention的面纱已经揭开,但还没有结束,因为上面的步骤如果写成代码,需要大量的for循环,显然效率太低,所以需要进行向量化,能合并成向量的合成向量,能合并成矩阵的合成矩阵。
1.7. 向量化
向量$a$ 的矩阵化,假设列向量 $a^i$ 维度为 $d$,显然可以将输入转化为矩阵 $I$,公式为:
$$ \begin{aligned} I_{d\times n} = (a^1, a^2, \cdots, a^n) \end{aligned} $$
接下来定义 $W^q, W^k, W^v$ 矩阵,其中$W^q$和$W^k$的矩阵维度必须一致,为$d_k\times d$,而$W^v$的矩阵维度为$d_v\times d$,其中 $d_k $和 $d_v$ 都是需要调的超参数(一般与词向量的维度 $d$ 保持一致)。$d_k$ 只影响过程,但 $d_v$ 会影响结果,即 $d_v$ 是Attention的输出向量 $b$ 的维度。 定义好 $W^q$ 的维度后,就可以将 $q$ 矩阵化了,
向量 $q$ 的矩阵化,公式为:
$$ \begin{aligned} Q_{d_k\times n} = (q^1, q^2, \cdots, q^n) = W^q_{d_k\times d} \cdot I_{d\times n} \end{aligned} $$
同理,向量k的矩阵化,公式为:
$$ \begin{aligned} K_{d_k\times n} = (k^1, k^2, \cdots, k^n) = W^k \cdot I \end{aligned} $$
同理,向量v的矩阵化,公式为:
$$ \begin{aligned} V_{d_v\times n} = (v^1, v^2, \cdots, v^n) = W^v \cdot I \end{aligned} $$
得到了矩阵$Q$和$K$,那么就很容易得出相关分数 $\alpha$ 的矩阵了,
相关分数 $\alpha$ 的矩阵为:
$$ \begin{aligned} A_{n\times n} = \begin{bmatrix} \alpha_{1,1} & \alpha_{2,1} & \cdots &\alpha_{n,1} \\ \alpha_{1,2} & \alpha_{2,2} & \cdots &\alpha_{n,2} \\ \vdots & \vdots & &\vdots \\ \alpha_{1,n} & \alpha_{2,n} & \cdots &\alpha_{n,n} \\ \end{bmatrix} = K^T \cdot Q =\begin{bmatrix} {k^1}^T \\ {k^2}^T \\ \vdots \\ {k^n}^T \end{bmatrix} \cdot (q^1, q^2, \cdots, q^n) \end{aligned} $$
我的定义 $k^i$ 是列向量,所以要转置一下
进一步,$\alpha '$ 的矩阵为:
$$ \begin{aligned} A'_{n\times n} = \textbf{softmax}(A) = \begin{bmatrix} \alpha'_{1,1} & \alpha'_{2,1} & \cdots &\alpha'_{n,1} \\ \alpha'_{1,2} & \alpha'_{2,2} & \cdots &\alpha'_{n,2} \\ \vdots & \vdots & &\vdots \\ \alpha'_{1,n} & \alpha'_{2,n} & \cdots &\alpha'_{n,n} \\ \end{bmatrix} \end{aligned} $$
$A'$ 有了,$V$ 有了,那就可以对输出向量 $b$ 进行矩阵化了,
输出向量b的矩阵化,公式为:
$$ \begin{aligned} O_{d_v\times n} = (b^1, b^2, \cdots, b^n) = V_{d_v\times n} \cdot A'_{n\times n} = (v^1, v^2, \cdots, v^n) \cdot \begin{bmatrix} \alpha'_{1,1} & \alpha'_{2,1} & \cdots &\alpha'_{n,1} \\ \alpha'_{1,2} & \alpha'_{2,2} & \cdots &\alpha'_{n,2} \\ \vdots & \vdots & &\vdots \\ \alpha'_{1,n} & \alpha'_{2,n} & \cdots &\alpha'_{n,n} \\ \end{bmatrix} \end{aligned} $$
将上面全部整合起来,就可以的到,整合后的公式为
$$ \begin{aligned} O = \textbf{Attention}(Q, K, V) = V\cdot \textbf{softmax}(K^T Q) \end{aligned} $$
如果你看过其他文章,你应该会看到真正的最终公式如下:
$$ \begin{aligned} \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \end{aligned} $$
其实我们的公式和这个公式只差了一个转置和 $\sqrt{d_k}$ 。转置不比多说,就是表示方式不同。
原公式的$Q,K,V$以及输出$O$,对应我们公式的 $Q^T,K^T,V^T$和 $O^T$
1.8. $d_k$是什么,为什么要除以 $\sqrt{d_k}$
首先,$d_k$是Q和K矩阵的行维度,也就是上面的 $Q_{d_k\times d}$中的 $d_k$ 。而矩阵相乘会放大原有矩阵的标准差,放大的倍数约为$\sqrt{d_k}$,为了将标准差缩放回原来的大小,所以要除以 $\sqrt{d_k}$。
例如,假设 $Q_{n \times d_k}$ 和 $K_{n\times d_k}$ 的均值为0,标准差为1。则矩阵 $QK^T$ 的均值为0,标准差为 $\sqrt{d_k}$,矩阵相乘使得其标准差放大了 $\sqrt{d_k}$倍
矩阵的均值就是把所有的元素加起来除以元素数量,方差同理。
可以通过以下代码验证这个结论(数学不好,只能通过实验验证结论了,哭):
```python
Q = np.random.normal(size=(123, 456)) # 生成均值为0,标准差为1的 Q和K
K = np.random.normal(size=(123, 456))
print("Q.std=%s, K.std=%s, \nQ·K^T.std=%s, Q·K^T/√d.std=%s"
% (Q.std(), K.std(),
Q.dot(K.T).std(), Q.dot(K.T).std() / np.sqrt(456)))
```
Q.std=0.9977961671085275, K.std=1.0000574599289282,
Q·K^T.std=21.240017020263437, Q·K^T/√d.std=0.9946549289466212
通过输出可以看到,Q和K的标准差都为1,但是两矩阵相乘后,标准差却变为了 21.24, 通过除以 $\sqrt{d_k}$,标准差又重新变为了 1
再看另一个例子,该例子Q和K的标准差是随机的,更符合真实的情况:
```python
Q = np.random.normal(loc=1.56, scale=0.36, size=(123, 456)) # 生成均值为随机,标准差为随机的 Q和K
K = np.random.normal(loc=-0.34, scale=1.2, size=(123, 456))
print("Q.std=%s, K.std=%s, \nQ·K^T.std=%s, Q·K^T/√d.std=%s"
% (Q.std(), K.std(),
Q.dot(K.T).std(), Q.dot(K.T).std() / np.sqrt(456)))
```
Q.std=0.357460640868945, K.std=1.204536717914841,
Q·K^T.std=37.78368871510589, Q·K^T/√d.std=1.769383337989377
可以看到,最开始Q的标准差为 $0.35$, K的标准差为 $1.20$,结果矩阵相乘后标准差达到了 $37.78$, 经过缩放后,标准差又回到了$1.76$。
1.9. 代码实战:Pytorch定义SelfAttention模型
接下来使用Pytorch来定义SelfAttention模型,这里使用原论文中的公式:
$$ \begin{aligned} \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \end{aligned} $$
这里为了使代码定义逻辑更清晰,下面我将各个部分的维度标记出来:
$$ \begin{aligned} O_{n\times d_v} = \text { Attention }(Q_{n\times d_k}, K_{n\times d_k}, V_{n\times d_v})&=\operatorname{softmax}\left(\frac{Q_{n\times d_k} K^{T}_{d_k\times n}}{\sqrt{d_k}}\right) V_{n\times d_v} \\\\ & = A'_{n\times n} V_{n\times d_v} \end{aligned} $$
其中,各个变量定义为:
- $n$:input_num,输入向量的数量,例如,你一句话包含20个单词,则该值为20
- $d_k$:dimension of K,Q和K矩阵的行维度(超参数,需要自己调,一般和输入向量维度 $d$ 一致即可),该值决定了线性层的宽度。
- $d_v$:dimension of V,V矩阵的行维度,该值为输出向量的维度(超参数,需要自己调,一般取值和输入向量维度 $d$ 保持一致)。
上述公式中,$Q,K,V$是通过矩阵 $W^q,W^k,W^v$和输入向量 $I$ 计算出来的,而一般对于要训练的矩阵,代码中一般使用线性层来表示,详情可参考:Pytorch nn.Linear的基本用法,所以最终 $Q$ 矩阵的计算公式为:
$$ \begin{aligned} Q_{n \times d_k} = I_{n\times d} W^q_{d\times d_k} ~~~~~~~~(2) \end{aligned} $$
$K,V$ 矩阵同理。其中
- $d$:input_vector_dim: 输入向量的维度,例如你将单词编码为了10维的向量,则该值为10
有了公式(1)和(2),就可以定义SelfAttention模型了,代码如下:
```python
class SelfAttention(nn.Module):
def __init__(self, input_vector_dim: int, dim_k=None, dim_v=None):
"""
初始化SelfAttention,包含如下关键参数:
input_vector_dim: 输入向量的维度,对应上述公式中的d,例如你将单词编码为了10维的向量,则该值为10
dim_k: 矩阵W^k和W^q的维度
dim_v: 输出向量的维度,即b的维度,例如,经过Attention后的输出向量b,如果你想让他的维度为15,则该值为15,若不填,则取input_vector_dim
"""
super(SelfAttention, self).__init__()
self.input_vector_dim = input_vector_dim
# 如果 dim_k 和 dim_v 为 None,则取输入向量的维度
if dim_k is None:
dim_k = input_vector_dim
if dim_v is None:
dim_v = input_vector_dim
"""
实际写代码时,常用线性层来表示需要训练的矩阵,方便反向传播和参数更新
"""
self.W_q = nn.Linear(input_vector_dim, dim_k, bias=False)
self.W_k = nn.Linear(input_vector_dim, dim_k, bias=False)
self.W_v = nn.Linear(input_vector_dim, dim_v, bias=False)
# 这个是根号下d_k
self._norm_fact = 1 / np.sqrt(dim_k)
def forward(self, x):
"""
进行前向传播:
x: 输入向量,size为(batch_size, input_num, input_vector_dim)
"""
# 通过W_q, W_k, W_v矩阵计算出,Q,K,V
# Q,K,V矩阵的size为 (batch_size, input_num, output_vector_dim)
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# permute用于变换矩阵的size中对应元素的位置,
# 即,将K的size由(batch_size, input_num, output_vector_dim),变为(batch_size, output_vector_dim,input_num)
# 0,1,2 代表各个元素的下标,即变换前,batch_size所在的位置是0,input_num所在的位置是1
K_T = K.permute(0, 2, 1)
# bmm是batch matrix-matrix product,即对一批矩阵进行矩阵相乘
# bmm详情参见:https://pytorch.org/docs/stable/generated/torch.bmm.html
atten = nn.Softmax(dim=-1)(torch.bmm(Q, K_T) * self._norm_fact)
# 最后再乘以 V
output = torch.bmm(atten, V)
return output
```
接下来使用一下,定义50个为一批(batch_size=50),输入向量维度为3, 一次输入5个向量,欲经过Attention层后,编码成5个4维的向量:
```python model = SelfAttention(3, 5, 4) model(torch.Tensor(50,5,3)).size() ```
torch.Size([50, 5, 4])
Attention模型一般作为整体模型的一部分,是套在其他模型中使用的,最经典的莫过于Transformer
二. MultiHead Attention 和 Masked Attention
MultiHead Attention 和 Masked Attention 请参考下篇MultiHead-Attention和Masked-Attention的机制和原理
参考资料
李宏毅Self-Attention: https://www.youtube.com/watch?v=hYdO9CscNes
超详细图解Self-Attention: https://zhuanlan.zhihu.com/p/410776234
Pytorch nn.Linear的基本用法:https://blog.csdn.net/zhaohongfei_358/article/details/122797190
极简翻译模型Demo,彻底理解Transformer:https://zhuanlan.zhihu.com/p/360343417
annotated-transformer:https://github.com/harvardnlp/annotated-transformer/



