【论文精读】迈向多标签未知意图检测 Towards Multi-label Unknown Intent Detection

文章目录
论文内容
论文年份:2022
论文地址 :https://yawenouyang.github.io/about/files/coling2022.pdf
论文代码地址(官方) :https://github.com/yawenouyang/AIK
视频解说(官方): https://www.bilibili.com/video/BV1je4y1B7rZ/
论文内容:该论文开辟了一个新的NLP任务多标签未知意图检测(Multi-label Unknown Intent Detection)。该任务是对Multi-class Unknown Intent Detection的扩展。该论文并提出了自己的一种模型来解决该问题。
1. 任务介绍(Multi-label Unknown Intent)
传统的Multi-class Unknown Intent Detection任务介绍: 人们的话语会存在意图(Intent)。例如:“今天天气怎么样?”的意图为“问天气”;“导航去南京”的意图为“导航”。由于意图有无限种,所以模型不可能识别所有的意图,所以我们要构建一个辅助模型,来找出哪些是意图是模型所不能识别的。
Unknown Intent通常也被称为Open Intent
传统意图识别任务的问题:传统的Unknown Intent Detection任务有个问题,就是假设一句话只有一个意图。但在现实中往往会出现一句话有多个意图的情况,例如“导航南京,那天气怎么样?”这句话中同时包含两个意图“导航”和“问天气”。对于这种语料,传统的模型可能就会将其归为“导航”这个意图,而忽略了“问天气”。
Multi-label Unknown Intent Detection任务介绍:针对传统意图识别的问题,作者提出了多标签未知意图检测任务。即检测包含多个意图的一句话中,是否存在未知意图。若存在,则将该语料归为OOD(Out-of-distribution),若不存在,则归为IND(In-distribution)
作者并不会检测出一句话都包含哪些意图,这些意图哪些是已知的(Known),哪些是未知的(Unknown)。而只是单纯的检测这句话中是否包含未知意图。
作者针对该任务将语料分为三种类型:
- IND utterances(In-distribution utterances) :仅包含已知意图的语料。例如:“导航去南京,那天气怎么样?”包含两个意图,这两个意图都在模型的识别范围内。
- Pure OOD utterances(Pure Out-of-distribution utterances) :仅包含未知意图的语料。例如:“查下我是不是绿码?还有多久解封?”,该预料包含了两个意图,且都是未知意图。
- mixed OOD utterances(mixed Out-of-distribution utterances):混合已知意图和未知意图的语料。例如:“导航去南京,查下那几天一检?”包含两个意图,其中“导航”为已知意图,“查政策”是未知意图。
2. 论文方法与模型
论文提出的方法为:All Intent of the utterance are Known,简称AIK。
基本思路为:第一步,首先预测出语料中包含几个意图,记为 $r$ .;第二步:找出当前语料距离哪 $r$ 个已知意图中心点最近,那么就认为当前语料包含哪几个意图。对于选择出的这几个意图,判断距离意图中心点最远的那个是否大于某个阈值,如果超过了该阈值,就认为该语料是OOD数据。
作者提出的模型如下图:
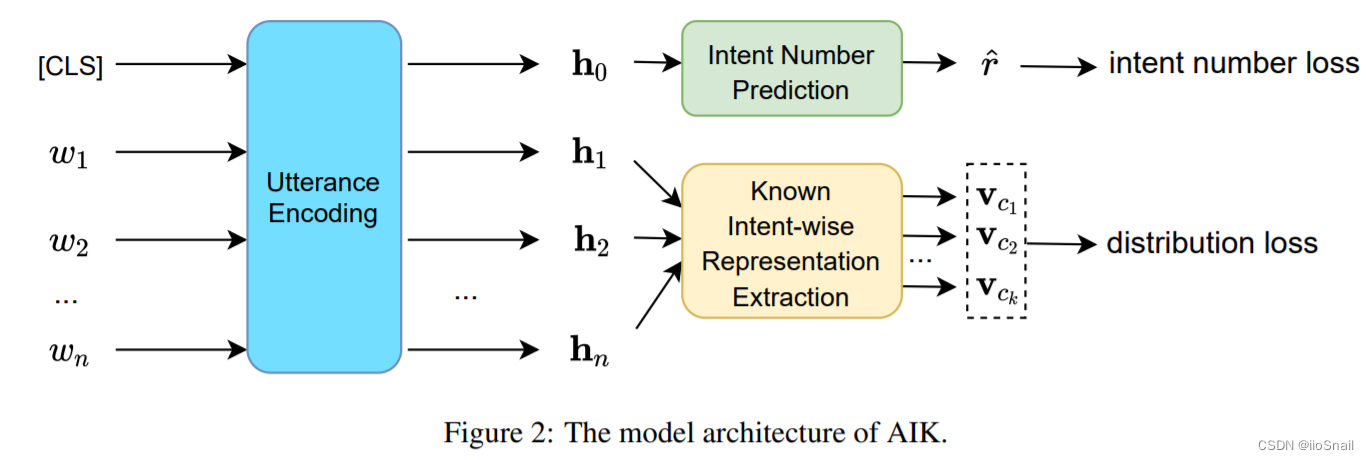
其中,Utterance Encoding是BERT(当然也可以不使用BERT)。
首先,第一步,预测语料的意图数 $r$。具体做法为:作者使用[CLS]的向量表示 $h_0$ 进行意图数量的预测。对于预测层,直接使用一个全连接网络完成。pytorch代码表示如下:
```python # 输入特征数为bert的hidden_size, 输出特征数为1,即输出一个数字,表示该语料包含的意图数。 nn.Linear(hidden_size, 1) ```
第二步,判断 $r$ 个意图都是有哪些,使用“置信度”最低的那个来判断该语料是否为OOD数据。 该步骤比较复杂,具体步骤为:
2.1 首先使用语料token $\{w_1, w_2, \dots, w_n\}$ 的BERT向量表示 $\{h_1, h_2, \dots, h_n\}$ 构造出每个意图的向量表示 $\{v_{c_1}, v_{c_2}, \dots, v_{c_k}\}$。其中 $c_k$是模型能够识别的意图类别数。对应图中Known Intent-wise Representation Extraction模块。 输出Shape为(batch_size, intent_num, hidden_size),例如(4, 3, 768)表示4个语料,每个语料包含3个已知意图的向量表示,每个意图表示为768维的向量。详情见2.1章节。
2.2 计算当前语料每个意图表示与其意图中心点的距离。直接使用相减的方式即可。意图中心点的计算方式详见2.2章节。
2.3 得到当前语料距离每个意图表示距离对应意图中心点的距离后,找出最小的前 $r$ 个作为结果。
2.4 拿2.3的结果进行阈值比较,若距离超过了设定的阈值,则认为该意图结果无效,将其归为未知意图。
上述的描述看起来比较难懂,接下来使用一个具体的例子来阐述上述过程。
假设:
- 模型已知意图有三个“导航”、“查天气”、“打电话”。
- 语料为: “导航去南京,那需要做核酸吗?”。包含两个意图“导航”(已知意图)和“查政策”(未知意图)。属于Mixed OOD语料。
- BERT模型的hidden size为768
则模型的推理过程如下:
第一步,将 “导航去南京,那需要做核酸吗?” 送入BERT得到[CLS]与tokens的向量表示。 BERT输出Tensor的Shape为(15, 768)(忽略了batch_size和[pad]token)。然后使用[CLS]的向量表示送给全连接网络预测意图数量,结果为2,表示该句话表示两个意图。
第二步:找出上述的 2 个意图都是什么,有几个未知意图。具体为:
2.1. 将BERT表示送给Known Intent-wise Representation Extraction模块,提取该语料对于每种意图的向量表示。输出Shape为(3, 768),即“导航”、“查天气”、“打电话”三种意图的向量表示。
2.2. 计算每个意图向量到每种意图向量的距离。输出为3个数,为 0.1(导航), 3.5(查天气), 1.5(打电话)。
2.3. 找出前 2 小的意图距离,即 0.1(导航),1.5(打电话)。
2.4. 将其距离与阈值 $1$ 比较,大于1的为未知意图,小于1的为已知意图。则最终得出结论:该预料包含2个意图,一个是“导航”,另一个是未知意图。
在原论文中,作者是对距离加了个负号,然后求前 $r$ 大的值,效果是一样的。
2.1 Known Intent-wise Representation Extraction模块
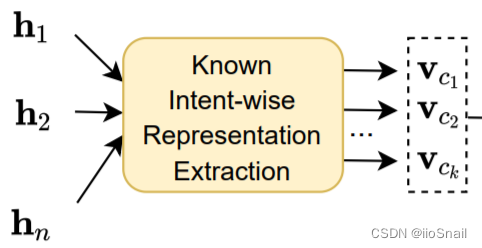
Known Intent-wise Representation Extraction模块的作用是:将语料表示成每个已知意图。
例如:
$\{h_1, h_2, \dots, h_n\}$ 对应“今 天 天 气 怎 么 样 ?”对应token的BERT向量表示,$n=8$
模型能够识别三种意图“查天气”,“导航”,“打电话”,那么$c_k=3$
则,该模块就是将“今天天气怎么样?”这个语料转换成三个向量 $v_{c_1}$, $v_{c_2}$, $v_{c_3}$, 分别表示该语料对应“查天气”、“导航”和“打电话”时的向量表示。
虽然语料中不一定包含模型所能识别的已知意图,也需要将其表示成每种已知意图的向量表示。这样是为了后续进行距离比较。例如:对于
今天天气怎么样?的查天气向量表示距离查天气的中心点比较近,其对应导航的向量表示就距离导航的中心点比较远。
上述解释了Known Intent-wise Representation Extraction模块的入参出参和作用,接下来讲解具体的提取方法。其思想为:利用Self-Attention中的query机制来计算语料中每个token对每种意图的权重,然后将所有token的BERT表示加权平均。
具体做法为:
- 将BERT的输出 $\{h_1, h_2, \dots, h_n\}$ 送给全连接层,得到每个意图对于每个token权重分布。用代码表示为:
```python """ 输入特征数为bert的hidden_size 输出特征数为已知意图数量(in-distribution intent num) """ self.query = nn.Linear(hidden_size, ind_intent_num, bias=False) ```
对应forward中的代码为:
```python
"""
output: bert输出的h_0, h_1, ..., h_n。 Shape为(batch_size, token_num, hidden_size),
例如Shape为(4, 16, 768)表示4个语料,每个预料16个token,每个token的向量表示为768维
weight: 每个token对应每个意图的权重。Shape为(batch_size, token_num, intent_num)。
例如Shape为(4, 16, 3)表示4个预料,每个预料16个token,共三个意图。
"""
weight = self.query(output) # weight: (batch_size, token_num, intent_num)
weight = torch.transpose(weight, 1, 2) # weight: (batch_size, intent_num, token_num)
"""
进行softmax对分布进行归一化。
例如,对于[<cls>, 今天, 天气, 怎么样, ?, <pad>, <pad>]这个sequence的结果可能为:
"查天气"意图: [0.01(<cls>), 0.09(今天), 0.8(天气), 0.09(怎么样), 0.01(?), 0(<pad>), 0(<pad>)]
"导航" 意图: [0.2(<cls>), 0.2(今天), 0.2(天气), 0.2(怎么样), 0.2(?), 0(<pad>), 0(<pad>)]
"打电话"意图: [0.2(<cls>), 0.2(今天), 0.2(天气), 0.2(怎么样), 0.2(?), 0(<pad>), 0(<pad>)]
对于"查天气"意图,`天气`token的权重很大。但对于“导航”和“打电话”意图所有的token权重都差不多,因为这个语料本来也不包含这俩意图。
"""
weight = self.masked_softmax(weight, mask) # weight: (batch_size, intent_num, token_num)
```
虽然图中在计算意图表示时并没有包含
[CLS]token,但我看作者的源码中还是将其包含进来了。
- 在计算好各token的权重后,就按照权重,对token进行加权平均,得到每种意图的表示。用pytorch代码表示为:
```python # 根据token进行加权平均。 rep = torch.bmm(weight, output) # representation: (batch, intent, hidden) ```
最终的Shape为(batch_size, intent_num, hidden_size),例如(4, 3, 768)表示4个语料,每个语料包含3个已知意图的向量表示,每个意图表示为768维的向量。
2.2 意图中心点计算
作者对意图中心点的初始化使用了两种不同的方法。
方法一:直接随机初始化。
方法二:Max-Mahalanobis center
最终的为每一种意图生成一个中心点,最终Shape为(intent_num, hidden_size)。例如:Shape为(3, 768)表示有3个已知意图,向量维度为768。
使用代码表示为:
```python
if not self.args.use_mmc:
# 使用随机初始化的意图中心点
self.mu = torch.rand(self.args.ind_intent_num, self.args.hidden_size).to(self.args.device)
self.mu.requires_grad = True
else: # 在论文的5.5章节详解
# 作者只在multiwoz23数据集上使用了该方法
assert self.args.dataset == 'multiwoz23'
self.mu = init_mmc_center(self.args, self.ind_set)
```
init_mmc_center的内容为:
```python
def init_mmc_center(args, ind_set):
def get_mmc(intent_num, feature_num, C):
mean = torch.zeros(intent_num, feature_num)
mean[0][0] = 1
for k in range(1, intent_num):
for j in range(k):
mean[k][j] = - (1 / (intent_num - 1) + torch.dot(mean[k], mean[j])) / mean[j][j]
mean[k][k] = torch.sqrt(torch.abs(1 - torch.norm(mean[k]) ** 2))
mean = mean * C
return mean
domain_count = defaultdict(int)
for intent in ind_set:
domain_count[intent.split('-')[1]] += 1
mean = torch.zeros(len(ind_set), args.hidden_size)
first_mean = get_mmc(len(domain_count), args.hidden_size, 5)
for i1, (domain, count) in enumerate(domain_count.items()):
last_mean = get_mmc(count, args.hidden_size, 2)
used_count = 0
for i2, intent in enumerate(ind_set):
if intent.split('-')[1] == domain:
mean[i2] = first_mean[i1] + last_mean[used_count]
used_count += 1
mean = mean.to(args.device)
return mean
```
3. 损失函数设计
Intent Number Loss:
对于意图数的损失,作者使用的是MSE(mean-squared error)。
```python self.intent_num_criterion = torch.nn.MSELoss() ```
forward为:
```python # pred_intent_num为预测的数量,由于是神经网络的输出,基本为小数,甚至为负数。 # golden_intent_num为真实值 intent_num_loss = self.intent_num_criterion(pred_intent_num, golden_intent_num) ```
对于known intent-wise representations模块,由两个损失构成。① 尽可能每种意图向量表示与实际意图向量中心点尽可能的近。② 尽可能让非语料实际意图的意图表示距离其对应的意图中心远。
① 使用的是类似MSE的损失函数,代码如下:
```python
def pos_loss(self, output, y):
"""
:param output: 网络输出的每个语料对于每种意图的向量表示
:param y: 每个语料实际的意图。
例如[[1], [0,1]],表示2个语料。第一个语料包含1个意图,意图为1
第二个语料包含两个意图,意图分别为0,1
"""
golden_center = torch.tensor([]).to(self.args.device)
golden_output = torch.tensor([]).to(self.args.device)
for index, one_y in enumerate(y):
# 获取y中的每个意图的意图中心点
golden_center = torch.cat((golden_center, self.mu[one_y]), dim=0)
# 获取网络输出对应真实意图的向量表示
golden_output = torch.cat((golden_output, output[index][one_y]), dim=0)
# batch_size: 并非dataloader的batch_size,而是这批语料中包含的意图总数
bsz = len(golden_center)
# 让网络输出的意图向量表示尽可能的接近真实意图中心
return torch.pow(golden_output - golden_center, 2).sum() / (2 * bsz)
```
② 同样使用类似MSE的损失函数,代码如下:
```python
def neg_loss(self, output, y):
"""
:param output: 网络输出的每个语料对于每种意图的向量表示
:param y: 每个语料实际的意图。
例如[[1], [0,1]],表示2个语料。第一个语料包含1个意图,意图为1
第二个语料包含两个意图,意图分别为0,1
"""
wrong_output = torch.tensor([]).to(self.args.device)
wrong_center = torch.tensor([]).to(self.args.device)
for index, one_y in enumerate(y):
# 真实意图之外的意图
wrong_y = [i for i in range(self.args.ind_intent_num) if i not in one_y]
# 获取非真实意图的意图表示
wrong_output = torch.cat((wrong_output, output[index][wrong_y]), dim=0)
# 获取非真实意图的意图中心点
wrong_center = torch.cat((wrong_center, self.mu[wrong_y]), dim=0)
# batch_size: 为 batch_size*已知意图数 - 这批语料中包含的意图总数
bsz = len(wrong_output)
# margin为300,relu相当于max(0, x)
return F.relu(self.args.margin - torch.pow(wrong_output - wrong_center, 2).sum(dim=1)).sum() / (2 * bsz)
```
对于第二个损失,这里要好好解释一下:
假设我们的语料为:导航去南京?,模型的已知意图为导航、问天气和打电话三个。我们的模型资源会对语料得到这三种意图的向量表示。对于第一个损失,我们是希望该预料的导航向量表示和导航意图的中心点尽可能的近。对于第二个损失,则是希望该预料的问天气和打电话这两个意图向量表示距离这两个意图的中心点尽可能的远。
所以第二个损失就是:$L'$ = -torch.pow(wrong_output - wrong_center, 2).sum(dim=1),也就是给每个错误意图求一个与其中心点的距离的负值,该值负的越多越好。
但是为了防止某些异常数据把它拉的太远,我们就定义一个阈值,称为margin,例如300。即如果错误意图与其中心点的距离超过300,我就认为差不多了,损失就设为0。即 $L = max(0, 300 + L')$。而max函数通常使用relu来完成,最终就成了:
```python F.relu(self.args.margin - torch.pow(wrong_output - wrong_center, 2).sum(dim=1)).sum() / (2 * bsz) ```
最终,我们得到了三种损失。通过加权的方式进行求和,得到最终的损失:
```python loss = pos_loss * self.args.l1 + neg_loss * self.args.l2 + intent_num_loss * self.args.l3 ```
其中l1,l2,l3是超参,我看作者取的都是1。
4. 实验
4.1 数据集
作者使用了两种数据集:
- MixSNIPS: 该数据集包含7个已知意图。作者选择2个作为未知意图给验证集用。又选择两个作为未知意图给测试集用。所以对于性训练集来说,只有3个已知意图。
- MultiWOZ 2.3:该数据集包含8个领域共132个已知意图。作者选择了两个领域作为未知意图给验证集,又选择两个领域作为未知意图给测试集,最终剩下52个已知意图给训练集。(我运行代码发现只有49个已知意图)
作者处理后的数据划分如下表:
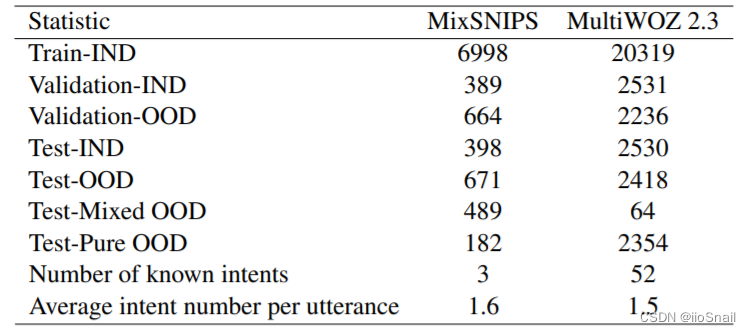
作者将数据集按大类划分成三种训练集、验证集和测试集:
- 训练集(Train-IND):训练集仅包含已知意图的数据。
- 验证集:分为两种 ①Validation-IND,仅包含已知意图;②Validation-OOD:包含Mixed OOD和Pure OOD的数据。
- 测试集:分为四种 ① Test-IND;②Test-OOD;③ Test-Mixed OOD;④ Test-Pure OOD;
这里的区分主要体现在metrics计算部分。在构造Dataset时,仅做了Train/Test/Validation的区分
4.2 Metrics
作者使用了如下的Metrics:
AUROC:the area under the true positive ratefalse positive rate curve;
总结(个人思考)
本文的缺点:
1.首先对于作者设置的任务,一个包含多个意图的句子,如果因为一个意图为未知意图,其整个句子就会被归为OOD。这样的设置在现实中显然是不合理的。
例如:在对话系统中,我可能会问智能客服。“帮我查下去南京坐哪班车,最早的一班几点。顺便看下明天需要带伞吗?需要几天内的核酸?”
此时,智能客服对于前几个问题都是可以回答的,但由于看不懂最后的“核酸”意图,直接将数据归为OOD,让其回答“您的问题太复杂我听不懂”,这样对于用户的体验太差了。
所以,我认为更合理的应该是:找出多意图语料中,已知意图有哪些,另外又包含了多少未知意图。



