(计算拼音相似度)DIMSIM 工具详解

工具信息
论文题目(提出工具的论文):DIMSIM: An Accurate Chinese Phonetic Similarity Algorithm Based on Learned High Dimensional Encoding
论文地址:https://aclanthology.org/K18-1043/
论文年份:2018-10
工具代码:https://github.com/System-T/DimSim
1. 拼音基础知识
拼音分为三个部分:
- 声母(initial):包含
'zh', 'ch', 'sh', 'b', 'p', 'm', 'f', 'd', 't', 'n', 'l', 'g', 'k', 'h', 'j', 'q', 'x', 'r', 'z', 'c', 's', 'y', 'w',共23个 - 韵母(final): 包含
'a', 'ai', 'an', 'ang', 'ao', 'e', 'ei', 'en', 'eng', 'er', 'i', 'ia', 'ian', 'iang', 'iao', 'ie', 'in', 'ing', 'iong', 'iu', 'o', 'ong', 'ou', 'u', 'ua', 'uai', 'uan', 'uang', 'ue', 'ui', 'un', 'uo', 'v', 've',共34个 - 声调(tone): 包含
'1', '2', '3', '4', '5',即1-4声和无声。
对于声母,即使字母不一样, 也会有具有相性,例如:p和b。声母的相似性特点可以汇总成下表:
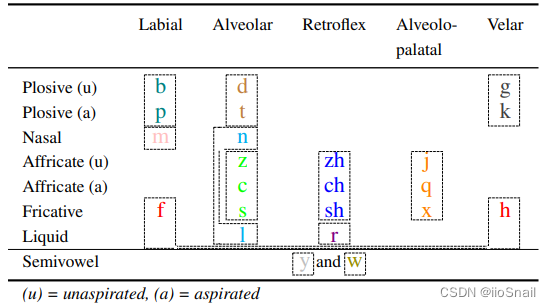
涉及的英文含义如下:
- Labial: 唇音。舌头不用动,用嘴唇就可以发音。
- Alveolar:齿音。发音时,舌尖顶住上门牙。
- Retroflex:卷舌音。发音时,舌头需要卷上去。
- Alveolo-palatal:舌面音。舌前方抵着或靠近硬腭前方,气流受阻后所产生的声音。
- Velar:软颚音。发音时,舌面后部接近软腭(就是舌头要塌下来)。
- Plosive:爆破音。
- Nasal:鼻音。
- Affricate:塞擦音。破擦音由一个爆破音和一个摩擦音组成。
- Fricative:摩擦音。
- Liquid: 流音。
- Semivowel:半元音:介于元音跟辅音之间的音段。
- unaspirated:不吐气。
- aspirated:吐气。
图中颜色相同(或者用虚线框起来的)属于发音相似的声母。一共有:“bp”,“dt”,“gk”,“hf”,“nl”,“r”, “jqx”, “zcs”, “zhchsh”, “m” ,“y” 和 “w”。
2. DIMSIM工具简介
作者提出了一种计算拼音相似度的方法,并将其制作成了Python库,可以很简单的使用安装。
使用方法:
- 安装依赖:
pip install dimsim - 计算相似度:
dimsim.get_distance("大侠","大虾"),输出0.0002380952380952381。或dimsim.get_distance(['da4','xia2'],['da4','xia1']], pinyin=True),输出0.0002380952380952381。
输出结果为距离,越小表示拼音越相似。
该工具有以下特点:
- 计算时字数必须相同,例如:
dimsim.get_distance("疼鞋", "同")会报错,因为字数不一致。 - 多个字计算的本质是计算每个字的相似度,然后相加。例如:
dimsim.get_distance("疼鞋", "同学")与dimsim.get_distance("疼", "同") + dimsim.get_distance("鞋", "学")等价。(这条不完全正确,只能说基本遵循这个规律) - 使用汉字和拼音无差别,因为本质就是先将汉字转换成拼音,然后再进行计算的。例如:
dimsim.get_distance("疼", "同")与dimsim.get_distance(['teng2'], ['tong2'], pinyin=True)等价。 - 方法本质是将“声母”、“韵母”和“声调”分别计算相似度,然后再相加。例如:
``` dimsim.get_distance(['teng2'], ['tong2'], pinyin=True) # 10.993710838681139 dimsim.get_distance(['meng2'], ['mong2'], pinyin=True) # 10.993710838681139 dimsim.get_distance(['meng3'], ['mong3'], pinyin=True) # 10.993710838681139 # 它们三个的输出一致,因为声母和声调都相同,只有韵母“eng和ong”不同,所以该例子本质就是计算“eng和ong”的相似度。 # 类似的例子: dimsim.get_distance(['meng3'], ['teng3'], pinyin=True) # 18.12028341946709 dimsim.get_distance(['mong3'], ['tong3'], pinyin=True) # 18.12028341946709 ```
- 该工具可以分清一些特殊的相似韵母(例如(p,b)相似度比(p,m)高)。例如:
dimsim.get_distance(['bang4'], ['pang4'], pinyin=True)为0.47,而dimsim.get_distance(['bang4'], ['mang4'], pinyin=True)为23.37 - 声调(tone)在相似度比重很低,大约在0.01%~1%之间。例如:
``` dimsim.get_distance(['wo1'], ['wo1'], pinyin=True) # 0 dimsim.get_distance(['wo1'], ['wo2'], pinyin=True) # 0.00047619 # 上面两个差了一个音调,距离差了0.0005,约占它们距离的0.05%. ```
- 音调的距离计算本质是通过的后面的数字相减,例如5音调距离1音调最远,2距离1音调较近。例如:
dimsim.get_distance(['wo1'], ['wo5'], pinyin=True)与dimsim.get_distance(['wo1'], ['wo2'], pinyin=True) * 4输出相同,即“5-1=(2-1)*4”。(基本遵循了这个规律,因为最后还有做一些除法) - 这个工具也不是完全准确。例如:“(你,一)”这两个挺像的吧,但是
dimsim.get_distance("你", "一")输出68008.53。(这是由Bug引起的)
3. 核心源码
core/model.py:
```python
# 获取两个文本的距离
def get_distance(utterance1, utterance2, pinyin=False):
...
# 若传不是拼音,则转成拼音
if not pinyin:
u1 = to_pinyin(utterance1) # 例如:"鸡你太美"转成"['ji1', 'ni3', 'tai4', 'mei3']"
u2 = to_pinyin(utterance2)
# 将拼音封装成Pinyin类
la = []
lb = []
for py in u1:
la.append(Pinyin(py))
for py in u2:
lb.append(Pinyin(py))
res = 0.0 # 记录总距离。拼音越不相似,该值越大
numDiff = 0 # 记录拼音的差异数量。
tot = len(utterance1)*2.1 # 总拼音数。2.1是为了和numDiff保持量纲一致。
# 逐个拼音进行比较
for i in range (len(utterance1)):
apy = la[i] # a pinyin
bpy = lb[i] # b pinyin
...
# 计算a,b拼音之间的距离
res += get_edit_distance_close_2d_code(apy, bpy)
# 若声母(initial)部分不一致,则差异数加1。例如:'z' != 'zh'
if apy.consonant is not bpy.consonant:
numDiff+=1
# 若韵母(final)部分不一致,则差异数加1。例如:'ing' != 'eng'
if not(str(apy.vowel) == str(bpy.vowel)):
numDiff+=1
# 若声调(tone)部分不一致,则差异数加0.01。例如:1声 != 3声
# 从这里可以看出,声调占比非常少。
if apy.tone is not bpy.tone:
numDiff+=0.01
# 适当减小总距离。当拼音的声母、韵母和声调都不通时,diffRatio=1。而有部分相同时,diffRatio<1
diffRatio = (numDiff)/tot
return res * diffRatio
```
个人认为源码中
tot = len(utterance1)*2.1和numDiff+=0.01应该是有一个写错了。要么都是0.01,要么都是0.1
utils/utils/py:
```python
# 计算两个拼音之间的距离
def get_edit_distance_close_2d_code(a, b):
res = 0
# 获取拼音的声母部分的坐标。例如:b为(1.0,0.5)。
# 作者将声母都映射到一个二维空间中,每个声母都具备自己的坐标,这个坐标是训练出来的。
twoDcode_consonant_a = consonantMap_TwoDCode[a.consonant]
twoDcode_consonant_b = consonantMap_TwoDCode[b.consonant]
# 求a,b拼音的声母坐标距离。这里求得是直线距离(欧拉距离)。例如:(0,0)与(1,1)的距离为 √2
cDis = abs(get_distance_2d_code(twoDcode_consonant_a, twoDcode_consonant_b))
# 与声母同理,每个韵母也有一个坐标。例如:ang为(1.0,1.5)
twoDcode_vowel_a = vowelMap_TwoDCode[a.vowel]
twoDcode_vowel_b = vowelMap_TwoDCode[b.vowel]
# 求a,b拼音韵母的坐标距离。
vDis = abs(get_distance_2d_code(twoDcode_vowel_a, twoDcode_vowel_b))
# 对于一些较为特殊的拼音组合,作者将其进行了写死(hard code)
# 若不是写死拼音,则hcDis=+无穷
hcDis = get_sim_dis_from_hardcod_map(a,b)
# 拼音距离=声母距离+韵母距离+声调距离/10
# 其中声调距离=声调相减。例如1声与4声的距离为4-1=3
res = min((cDis+vDis),hcDis) + 1.0*abs(a.tone-b.tone)/10
return res
```
源码中的声母坐标如下:
```python
consonantMap_TwoDCode = {
"b": (1.0, 0.5), "p": (1.0, 1.5),
"g": (7.0, 0.5), "k": (7.0, 1.5), "h": (7.0, 3.0), "f": (7.0, 4.0),
"d": (12.0, 0.5), "t": (12.0, 1.5),
"n": (22.5, 0.5), "l": (22.5, 1.5), "r": (22.5, 2.5),
"zh": (30, 1.7), "z": (30, 1.5), "j": (30.0, 0.5),
"ch": (31, 1.7), "c": (31, 1.5), "q": (31.0, 0.5),
"sh": (33, 3.7), "s": (33, 3.5), "x": (33, 2.5),
"m": (50.0, 3.5), "y": (40.0, 0.0), "w": (40, 5.0),
"": (99999.0, 99999.0) # 正常不应该出现这种情况。
}
```
韵母坐标系如下:
```python
vowelMap_TwoDCode = {
"a": (1.0, 0.0), "an": (1.0, 1.0), "ang": (1.0, 1.5),
"ia": (0.0, 0.0), "ian": (0.0, 1.0), "iang": (0.0, 1.5),
"ua": (2.0, 0.0), "uan": (2.0, 1.0), "uang": (2.0, 1.5), "u:an": (2.0, 1.0),
"ao": (5.0, 0.0), "iao": (5.0, 1.5),
"ai": (8.0, 0.0), "uai": (8.0, 1.5),
"o": (20, 0.0), "io": (20, 2.5), "iou": (20, 4), "iu": (20, 4), "ou": (20, 5.5), "uo": (20, 6.0),
"ong": (20, 8.0), "iong": (20, 9.5),
"er": (41, 1), "e": (41, 0.0),
"u:e": (40, 5.0), "ve": (40, 5.0), "ue": (40, 5.0), "ie": (40, 4.5), "ei": (40, 4.0), "uei": (40, 3.0),
"ui": (40, 3.0),
"en": (42, 0.5), "eng": (42, 1.0),
"uen": (43, 0.5), "un": (43, 0.5), "ueng": (43, 1.0),
"i": (60, 1.0), "in": (60, 2.5), "ing": (60, 3.0),
"u:": (61, 1.0), "v": (61, 1.0), "u:n": (61, 2.5), "vn": (61, 2.5),
"u": (80, 0.0),
"": (99999.0, 99999.0) # 正常不应该出现这种情况
}
```
源码BUG:
当拼音的声母为“y”或“w”时,拼音的距离就会非常大,例如:
```python get_distance(['wan1'], ['tan3'], pinyin=True) # 135351.09 get_distance(['man1'], ['tan3'], pinyin=True) # 18.39 get_distance(['yan1'], ['tan3'], pinyin=True) # 135351.09 ```
Bug原因:
因为pypinyin这个库在处理y和w这两个声母的时候,会将其归到韵母中。


