机器学习入门课程学习笔记(斯坦福吴恩达)

文章目录
- 一、简介
- 二、 模型和代价函数(Model and Cost Function)
- 三、线性代数
- 3.1 矩阵和向量
- 3.2 矩阵的加法和标量乘法(Addition and Scalar Multiplication)
- 3.2 矩阵与向量相乘(Matrix-vector Multiplication)
- 3.3 矩阵与矩阵相乘(Matrix-matrix Multiplication)
- 3.4 矩阵乘法的性质(Matrix Multiplication Properties)
- 3.5 矩阵的逆和转置(Inverse and Transpose)
- 四、多元线性回归(Multivariate Linear Regression)
- 4.1 多个特征(Multiple features)
- 4.2 多元线性回归中的梯度下降
- 4.3 梯度下降实战-特征缩放(Feature Scaling)
- 4.4 梯度下降实战-学习率(Learning Rate)
- 4.5 特征和多项式回归(Features and Polynomial Regression)
- 4.6 正规方程(Normal Equation)
- 4.7 正规方程不可逆(Normal Equation Noninvertibility)
- 五、Octave教程
- 六、逻辑回归
- 6.1 分类问题(Classification)
- 6.2 Hypothesis Representation
- 6.3 决策边界(Decision Boundary)
- 6.4 逻辑回归的代价函数
- 6.5 简化代价函数和梯度下降(Simplified Cost Function and Gradient Descent )
- 6.6 高级优化(Advanced Optimization)
- 6.7 多分类问题:一对多(Multiclass Classification: One-vs-all)
- 七、解决过拟合问题
- 7.1 过拟合问题
- 7.2 包含正则化的代价函数
- 7.3 正则化的线性回归(Regularized Linear Regression)
- 7.4 正则化的逻辑回归(Regularized Logistic Regression)
- 八、神经网络(Neural Networks)
- 8.1 非线性假设(Non-linear Hypotheses)
- 8.2 神经和大脑(Neurons and the Brain)
- 8.3 模型表示(Model Representation)
- 8.4 样例1(Examples and Intuitions)
- 8.5 多分类问题(Multiclass Classification)
- 九、神经网络(二)
一、简介
1.1 什么机器学习
机器学习的定义:一个计算机程序可从经验E(Experience)中学习如何完成任务T(Task),并且随着经验E的增加,性能指标P (performance measure)会不断提高
机器学习的分类:
- 监督学习(Supervised Learning):给定一个数据集,该数据集包含输出结果(标签),程序通过学习,来给输入数据打标签。例如:喂给程序n张动物图片,并且告知它每张图片是什么动物,程序经过学习后,喂给程序一张未打标签的图片,让程序判断这是什么动物
- 非监督学习(Unsupervised Learning):与监督学习正好相反。给定一个数据集,但不给出每个数据集的输出,让程序自己去给数据集进行分类。例如:给定一组基因数据,根据给定的变量(如寿命,地理位置等),自动将其进行分组。
1.2 监督学习(Supervised Learning)
给定一个数据集,该数据集包含输出结果(标签),程序通过学习,来给输入数据打标签。例如:喂给程序n张动物图片,并且告知它每张图片是什么动物,程序经过学习后,喂给程序一张未打标签的图片,让程序判断这是什么动物
监督学习问题的分类:
- 分类问题(Classification Problem):预测的结果是离散值。例如:要预测一张动物照片属于猫、狗或其它等。
- 回归问题(Regression Problem):预测的结果是连续值。例如:预测房屋的价格,结果可以是10000,10001, ...
1.3 非监督学习(Unsupervised Learning)
给定一个数据集,但是并不会告诉机器“每个数据集是什么”,然后让机器自己去对这个数据集进行分类。比如给定一组衣服尺寸数据,通过机器学习,将衣服分成“大”、“中”、“小”三类,训练好模型后,再给定一个衣服尺寸数据,机器就可以识别出这是大号还是中号或小号。
二、 模型和代价函数(Model and Cost Function)
2.1 模型描述(Model Representation)
- $m$ :训练数据集的样本数量
- $x^{(i)}$:第 $i$ 个样本的输入(特征)
- $y^{(i)}$: 第 $i$ 个样本的输出(目标值)
- $(x^{(i)}, y^{(i)})$:第 $i$ 个样本
- $\theta_0,\theta_1,\theta_2,\dots$ :要训练的参数
- $h_\theta(x)$ 或 $h(x)$:训练出的模型(函数)

2.2 代价函数(Cost Function)
代价函数是用来描述“当前模型预测的精确程度”,一般来说,代价函数的值越大,预测的值越不精准,所以,我们优化模型的其中一个目标就是使代价函数尽可能的小
代价函数表示方法不唯一,通常使用以下表示方法:
$$ \begin{aligned} J(\theta) = \frac{1}{2m} \sum_{i=1}^{m}(\hat{y}_i-y_i)^2 = \frac{1}{2m} \sum_{i=1}^{m}(h_\theta(x_i)-y_i)^2 \end{aligned} $$
公式解释:
- $J(\theta)$:代价函数,其中 $\theta$ 为当前的模型参数。目标就是不断优化参数 $\theta$ 来使代价函数的值变小
- $(\hat{y}_i-y_i)^2$:$\hat{y}$ 为预测的值,$y$ 为实际值。使用预测的值减去实际值,来求得误差值。加平方有两个原因:①消除负号 ②方便求导(如果使用绝对值会不方便求导)
- $\frac{1}{2m}$ : 除以 $m$ 是为了求平均。除以2为了方便求导,因为求导后,2次方会正好把这个2消掉
2.3 梯度下降(Gradient Descent)
梯度下降是用来找出当$\theta$ 取何值时,$J(\theta)$ 取“最小值” 。
核心思想:对 $J(\theta)$ 进行求导,算出当前$J(\theta)$的方向, 然后向着$J(\theta)$减小的方向移动 $\theta$,直到$\theta$ 趋于0
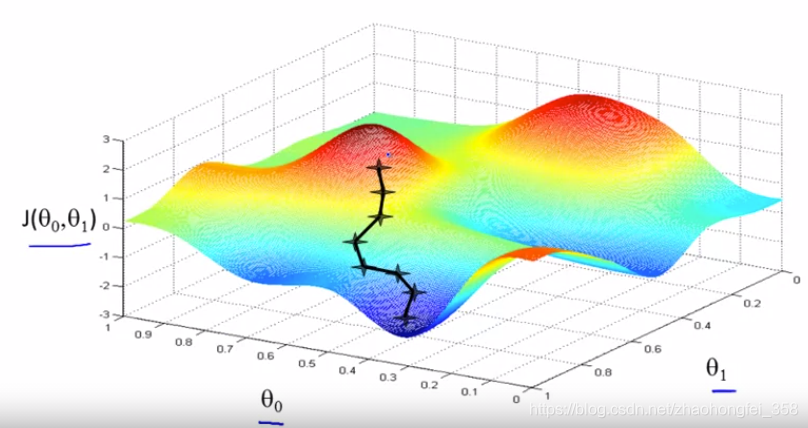
梯度下降算法伪代码:
$$ \begin{aligned} &repeat~~until ~~convergence ~~\{ \\ &~~~~~~~~ \theta_j ~:=~ \theta_j - \alpha\frac{\partial}{\partial \theta_j} J(\theta_0, \theta_1) ~~~~(for~~ j=0 ~ and ~ j=1)\\ &\} \end{aligned} $$
解释:
:=:赋值操作。在其他语言中,一般使用=,而非:=- repeat until convergence:重复直到收敛为止。不断重复括号里的操作,直到 $\theta_j$ 收敛于某一值,也就是 $J(\theta_0, \theta_1)$ 趋近于0
- $\theta_j ~:=~ \theta_j - \alpha\frac{\partial}{\partial \theta_j} J(\theta_0, \theta_1)$ :$\alpha$为一指定常数,称为学习率(learning rate)。每次 $\theta_j$ 向 $J(\theta_0, \theta_1)$ 减小的方向移动一点
- $(for~~ j=0 ~ and ~ j=1)$ : $j$ 为 $\theta$ 的下标,在该例中,有两个需要学习的参数,所以需要对 $\theta_0$ 和 $\theta_1$ 都做上面这个操作
$$ \begin{aligned} &Correct: Simultaneous~ update \\ & temp0 = \theta_0 - \alpha\frac{\partial}{\partial \theta_0} J(\theta_0, \theta_1) \\ & temp1 = \theta_1 - \alpha\frac{\partial}{\partial \theta_1} J(\theta_0, \theta_1) \\ & \theta_0 := temp0 \\ & \theta_1 := temp1 \\ \end{aligned} $$
需要注意:$\theta_0$ 和 $\theta_1$ 要同时更新,他们都更新后才能进入下一轮循环。
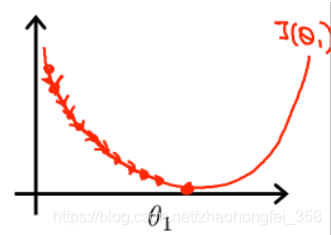
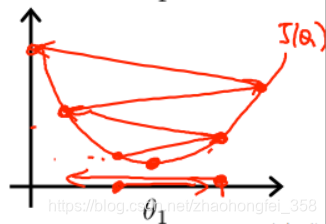
学习率 $\alpha$:学习率决定每次移动的步长
-
学习率太小:如果学习率太小,每次移动的就会太少。要找出最低点,就会需要循环更多次。
-
学习率太大:如果学习率太大,每次移动的步长太大,可能会导致无法收敛,甚至可能会发散。
三、线性代数
3.1 矩阵和向量
矩阵(Matrix):矩形的一组数字类型的数组,一般用大写字母表示。例如: $$ \begin{aligned} A=\begin{bmatrix} 123 & 444 \\ 454 & 1238 \\ 4264 & 1128 \\ \end{bmatrix} \end{aligned} $$
矩阵的维度(Dimension of matrix):矩阵是一个二维数组,维度用 $行数\times 列数$ 表示。例如,上面这个矩阵维度为 $3\times 2$,记作 $\mathbb{R}^{3\times 2}$
矩阵的元素(Matrix Elements ( entries of matrix )):$A_{ij}$ 表示矩阵 $A$ 中的第 $i$ 行 第 $j$ 列的元素。例如,$A_{11}=123$ ,$A_{32}=1128$
向量(Vector):一个 $n\times 1$ 的矩阵就是一个向量,一般用小写字母表示。例如: $$ \begin{aligned} y = \begin{bmatrix} 213 \\ 54 \\ 314 \\ \end{bmatrix} \end{aligned} $$
向量的元素:$y_i$ 表示向量的第 $i$ 个元素。例如 $y_2=54$
3.2 矩阵的加法和标量乘法(Addition and Scalar Multiplication)
矩阵的加法(Matrix Addition):两个矩阵相加得到一个新的矩阵。做法为对应元素相加,要求两个矩阵维度必须一样,要不然没法对应元素相加。例如: $$ \begin{bmatrix} 1 & 0 \\ 2 & 5 \\ 3 & 1 \\ \end{bmatrix} + \begin{bmatrix} 4 & 0.5 \\ 2 & 5 \\ 0 & 1 \\ \end{bmatrix} = \begin{bmatrix} 5 & 0.5 \\ 4 & 10 \\ 3 & 2 \\ \end{bmatrix} $$
标量乘法(Scalar Multiplication): 矩阵乘以一个数得到一个新的矩阵,做法为每个元素都乘以该数。例如: $$ \begin{aligned} 3 \times \begin{bmatrix} 1 & 0 \\ 2 & 5 \\ 3 & 1 \\ \end{bmatrix} = \begin{bmatrix} 3 & 0 \\ 6 & 15 \\ 9 & 3\\ \end{bmatrix} \end{aligned} $$
3.2 矩阵与向量相乘(Matrix-vector Multiplication)
矩阵与向量相乘(Matrix-vector Multiplication):矩阵乘以向量然后得到一个新的向量,做法为矩阵的每一个行的元素与向量元素对应相乘再相加。要求矩阵列的维度要和向量维度一致。例如: $$ \begin{bmatrix} 1 & 3 \\ 4 & 0 \\ 2 & 1\\ \end{bmatrix} \begin{bmatrix} 1 \\ 5 \\ \end{bmatrix} = \begin{bmatrix} 1\times 1+3\times 5\\ 4\times1+ 0\times5\\ 2\times1+1\times5\\ \end{bmatrix} = \begin{bmatrix} 16\\ 4\\ 7\\ \end{bmatrix} $$
3.3 矩阵与矩阵相乘(Matrix-matrix Multiplication)
矩阵与矩阵相乘(Matrix-matrix Multiplication):两个矩阵相乘得到一个新的矩阵,做法为第1个矩阵的 $i$ 行与第2个矩阵的 $j$ 列对应元素相乘再相加作为结果矩阵的第$i$行第$j$列的元素。要求第一个矩阵的列数要与第二个矩阵的行数一致。例如: $$ \begin{bmatrix} 1 & 3 & 2\\ 4 & 0 & 1\\ \end{bmatrix} \begin{bmatrix} 1 & 3\\ 0 & 1\\ 5 & 2\\ \end{bmatrix} = \begin{bmatrix} 1 \times 1+3\times 0+2\times 5 & 1\times 3+3\times 1+2\times 2\\ 4\times 1+0\times 0+1\times 5 & 4\times 3+0\times 1+1\times 2\\ \end{bmatrix} = \begin{bmatrix} 11 & 10\\ 9 & 14 \\ \end{bmatrix} $$
3.4 矩阵乘法的性质(Matrix Multiplication Properties)
- $A\times B \neq B\times A$
- $(A\times B) \times C = A\times (B \times C)$
- $n\times n$ 的矩阵称为方阵(square matrix)
-
对角线全为1,其余全为0的方阵称为单位矩阵(identity matrix),记作 $I$ 或 $E$ 。 例如: $$ \begin{bmatrix} 1 & 0 & 0\\ 0 & 1 & 0\\ 0 & 0 & 1\\ \end{bmatrix} $$
-
$A\cdot I=I \cdot A = A$
3.5 矩阵的逆和转置(Inverse and Transpose)
逆矩阵(inverse matrix):如果一个矩阵 $A$ 为方阵,且存在矩阵 $B$,满足 $AB=BA=I$,则称矩阵 $B$ 为矩阵 $A$ 的逆矩阵,记作 $A^{-1}$ 。即 $AA^{-1} = A^{-1}A=I$
逆矩阵的性质:
- 只有方阵才有逆矩阵,且与逆矩阵维度相同
- 不是所有矩阵都有逆矩阵
转置矩阵(transposed matrix):如果一个 $m\times n$ 矩阵 $A$ 和另一个 $n\times m$ 的矩阵 $B$ ,满足 $A_{ij} = B_{ji}$,则称 $B$ 矩阵为$A$矩阵的转置矩阵,记作 $A^T$ 。 例如: $$ \begin{aligned} A = \begin{bmatrix} 1 & 2 & 0 \\ 3 & 5 & 9 \\ \end{bmatrix} ~~~~~~则 ~~~A^T = \begin{bmatrix} 1 & 3 \\ 2 & 5 \\ 0 & 9 \\ \end{bmatrix} \end{aligned} $$
四、多元线性回归(Multivariate Linear Regression)
4.1 多个特征(Multiple features)
多元线性回归:有多个特征的线性回归问题
符号(Notation):
- $n$ :表示特征的数量
- $x^{(i)}$ :第 $i$ 个样本的输入
- $x_j^{(i)}$:第 $i$ 个样本的第 $j$ 个特征的值
多元线性回归方程:$h_\theta(x)=\theta_0 + \theta_1x_1 +\theta_2x_2 + \cdots + \theta_nx_n$
为了方便向量化,一般定义 $x_0=1$,同时记: $$ \begin{aligned} x = \begin{bmatrix} x_0 \\ x_1 \\ x_2 \\ \cdots \\ x_n \\ \end{bmatrix} \in \mathbb{R} ^{n+1} ~~~~~~~~~~~ \theta = \begin{bmatrix} \theta_0 \\ \theta_1 \\ \theta_2 \\ \cdots \\ \theta_n \\ \end{bmatrix}\in \mathbb{R} ^{n+1} \end{aligned} $$
则,线性回归方程为: $$ \begin{aligned} h_\theta(x) &=\theta_0x_0 + \theta_1x_1 +\theta_2x_2 + \cdots + \theta_nx_n \\\\ &= \theta^Tx \end{aligned} $$
4.2 多元线性回归中的梯度下降
假设(Hypothesis): $h_\theta(x)= \theta^Tx=\theta_0x_0 + \theta_1x_1 +\theta_2x_2 + \cdots + \theta_nx_n$
参数(Parameters): $\theta = (\theta_0, \theta_1, \cdots, \theta_n)^T$
代价函数(Cost function): $$\begin{aligned}J(\theta_0, \theta_1, \cdots, \theta_n) = \frac{1}{2m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})^2\end{aligned}$$
梯度下降:$$ \begin{aligned} &Repeat ~~\{ \\ & ~~~~~~~\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)} \\ &\} \\\\ & (注意要同时更新 ~\theta_j,~~~~j=0,1,\cdots, n) \end{aligned} $$
4.3 梯度下降实战-特征缩放(Feature Scaling)
问题提出: 若特征的量纲不一致,那么在进行梯度下降的时候,在量纲大的方向上下降过多,而在量纲小的方向下降过少。例如:
- $x_1$ = 房屋面积 (0 - 2000 m^2^)
- $x_2$ = 房间数量 (0-5)
那么在进行梯度下降时,就会产生一个特别椭的椭圆。
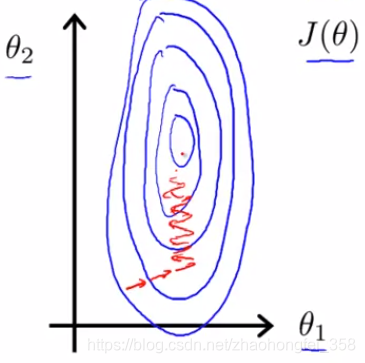
特征缩放(feature scaling):让每一个特征都缩放到 $[-1, 1]$ 之间,即 $-1\le x_i \le 1$
特征缩放常用方法(参考资料):
- 均值归一化(Mean Normalization) :使用 $x_i - \mu_i$ 替换 $x_i$,使特征的均值约等于0。公式为: $$\begin{aligned}x_{scale} = \frac{x-\mu}{S}\end{aligned}$$ 其中, $\mu$ 为 $x$ 对应特征的平均值,S为特征的范围之差(max-min),S也可以使用标准差。
4.4 梯度下降实战-学习率(Learning Rate)
随着梯度下降迭代次数的增多,$J(\theta)$也会越来越小,曲线大概如下图所示:
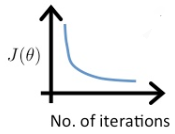
梯度下降的收敛:一般认为,当 $J(\theta)$ 在一次迭代后,减小的量小于 $10^{-3}$ ,则认为梯度下降已经收敛,可以退出循环了。
学习率 $\alpha$ 的总结:
- $\alpha$ 太小 : 收敛的太慢
- $\alpha$ 太大 :可能会导致不收敛,甚至发散。即每次 $J(\theta)$ 不减反增
学习率$\alpha$的选择:一般先选择一个很小的数,然后逐渐增大进行尝试。例如: ..., 0.001, 0.01, 0.1, 1, ...
4.5 特征和多项式回归(Features and Polynomial Regression)
由于预测的模型不一定是直线 $\theta_0+\theta_1x$,有可能是二次曲线、三次曲线、...
多项式回归:对一个特征,定义回归方程时,包含特征的高次方。 $$ \begin{aligned} h_\theta(x) = \theta_0 + \theta_1x + \theta_2x^2 + \theta_3x^3 + \cdots \end{aligned} $$
对于多项式回归方程,处理方式为将x的高次方当成其他特征进行处理即可:$x_1 = x ~~,~~~ x_2 = x^2 ~~,~~~ x_3 = x^3 ~~, ~~~ ...$
除了定义高次方外,也可以定义其他次方,例如 $$ \begin{aligned} h_\theta(x) = \theta_0 + \theta_1x + \theta_2x^2 + \theta_3\sqrt{x} \end{aligned} $$
4.6 正规方程(Normal Equation)
多元线性回归的正规方程解:不使用梯度下降法,而是通过数学公式,直接计算出 $\theta$
设有 $m$ 个样本 $(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}),\cdots, (x^{(m)},y^{(m)})$,每个样本有 $n$ 个特征,即: $$ \begin{aligned} x^{(i)} = \begin{bmatrix} x_0^{(i)} \\ x_1^{(i)} \\ x_2^{(i)} \\ \cdots \\ x_n^{(i)} \\ \end{bmatrix} \in \mathbb{R}^{n+1} ~~~~~~~~X = \begin{bmatrix} (x^{(1)})^T \\ (x^{(2)})^T \\ (x^{(3)})^T \\ \cdots \\ (x^{(m)})^T \\ \end{bmatrix}_{m\times (n+1)} \end{aligned} $$
则,使得 $J(\theta)$ 最小的 $\theta$ 为: $$ \begin{aligned} \theta = (X^T X)^{-1} X^Ty \end{aligned} $$
时间复杂度:O(n^3^) ,n为特征数
梯度下降法与正规方程法的比较:
| 梯度下降法 | 正规方程法 |
|---|---|
| 需要考虑学习率 $\alpha$ | 不需要选择学习率 |
| 需要多次迭代 | 需需要迭代 |
| 适用于特征比较多的场景,即 n 比较大 | 不适用与特征多的场景 |
4.7 正规方程不可逆(Normal Equation Noninvertibility)
在使用正规方程求解 $\theta$ 时,有可能出现 $X^TX$ 没有逆矩阵的情况。
主要有以下情况:
1.当特征中存在成比例的特征,则会导致不可逆(会导致 $|X|=0$),例如:
- $x_1$ = 房屋面积(m^2^)
- $x_2$ = 房屋面积 (亩)
解决方案:只保留一个
2.特征太多了,导致 $n\ge m$
解决方案:删除部分特征,或使用正则化(regularization)
五、Octave教程
略,现在不用学这个了,直接用Numpy不香么
六、逻辑回归
6.1 分类问题(Classification)
二分类问题:分类结果只包含两种类别,使用 $0,1$ 表示,即 $y\in \{0,1\}$。 其中 0 代表 Negative Class(例如良性肿瘤),1 代表 Positive Class(例如恶性肿瘤)。 具体0,1谁表示什么无所谓。
只使用线性回归处理的弊端:
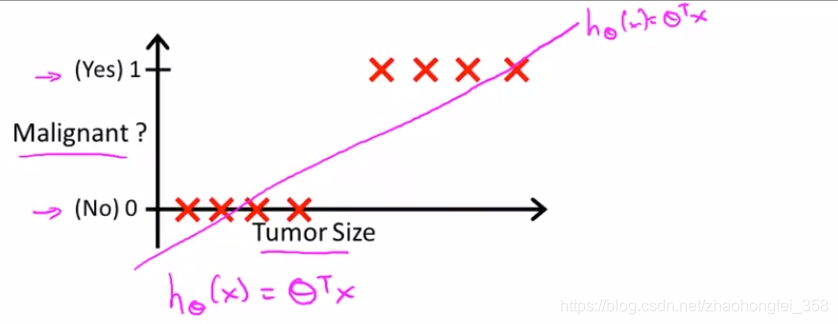
根据数据,得出以下模型:
- 如果 $h_\theta(x) \ge 0.5$ ,预测 $y=1$
- 如果 $h_\theta(x) < 0.5$ ,预测 $y=0$
但如果再增加一些极端的点,获得的模型就会如同下面蓝色线,这个模型显然不够好。
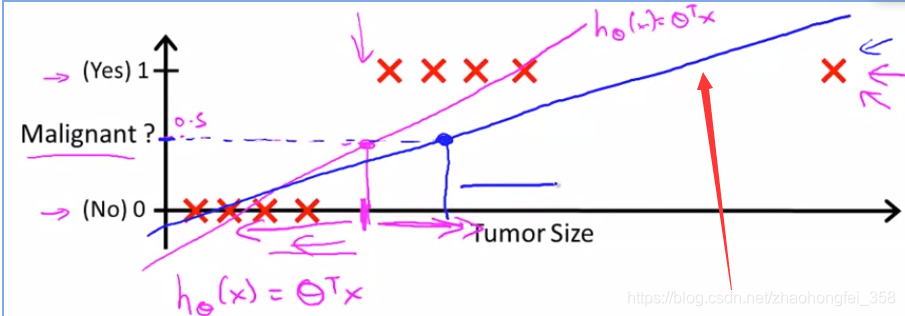
而且,线性回归的 $h_\theta(x)$ 可能 $>1$ 也可能 $<0$
而逻辑回归满足:$0 \le h_\theta(x) \le 1$
6.2 Hypothesis Representation
逻辑回归是处理二分类问题的
它需要使 $0 \le h_\theta(x) \le 1$
逻辑回归模型的假设公式为: $$ \begin{aligned} h_\theta(x) = g(\theta^Tx) =\frac{1}{1+e^{-\theta^Tx}}~~~~~其中 g(z) = \frac{1}{1+e^{-z}} \end{aligned} $$
$g(z)$ 被称为Sigmoid Function,其函数图像为:
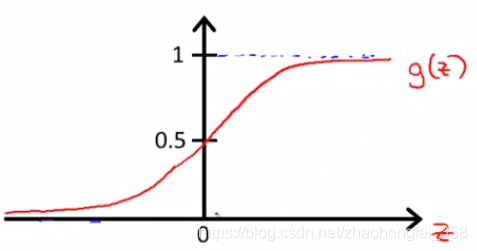
$h_\theta(x)$的结果为对于输入x,使得y=1的概率,即 $h_\theta(x) =P(y=1|x;\theta)$ 。例如:$h_\theta(x^{(1)}) = 0.7$,表示对于样本 $x^{(1)}$,$y=1$的概率为0.7
6.3 决策边界(Decision Boundary)
决策边界(Decision Boundary):将数据分成两个类比的边界线。
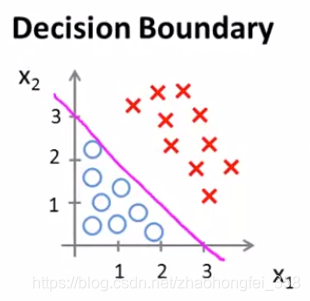
例如,我们经过训练得到了一条决策边界:$-3 + x_1+x_2 =0$
- 当样本 $-3 + x_1+x_2 \ge 0$ 时,$g(-3 + x_1+x_2) \ge 0.5$ , 预测为红X
- 当样本 $-3 + x_1+x_2 <0$ 时,$g(-3 + x_1+x_2) <0.5$ ,预测为蓝〇
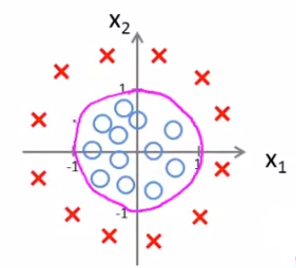
样例2,非线性的决策边界:$-1+x_1^2+x_2^2 = 0$
- 当 $-1+x_1^2+x_2^2 \ge 0$ 时, $g(-1+x_1^2+x_2^2)\ge 0.5$, 预测为红X
- 当 $-1+x_1^2+x_2^2 < 0$ 时, $g(-1+x_1^2+x_2^2) < 0.5$, 预测为蓝〇
6.4 逻辑回归的代价函数
逻辑回归的代价函数部分公式如下:
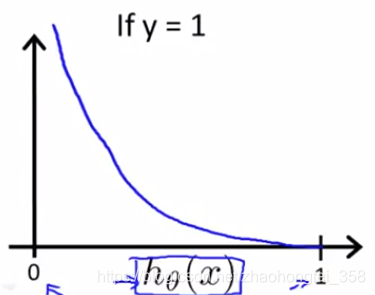
$$ \begin{aligned} Cost(h_\theta(x), y) = \begin{cases} -\log(h_\theta(x)) &\text{if } ~~y=1 \\ -\log (1-h_\theta(x)) &\text{if } ~~ y=0 \end{cases}~~~~~~\text{注意底数是} e,不是2 \end{aligned} $$
$-\log(h_\theta(x))$ 的函数图像如下,预测结果 $h_\theta(x)$ 越偏离真实结果1,那么代价就越大
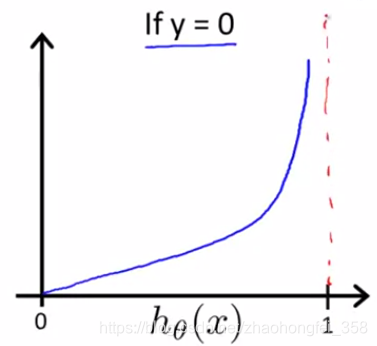
$-\log (1-h_\theta(x))$ 的函数图像如下,预测结果 $h_\theta(x)$ 越偏离真实结果0,那么代价就越大
6.5 简化代价函数和梯度下降(Simplified Cost Function and Gradient Descent )
梯度下降的代价函数部分公式如下: $$ \begin{aligned} Cost(h_\theta(x), y) = \begin{cases} -\log(h_\theta(x)) &\text{if } ~~y=1 \\ -\log (1-h_\theta(x)) &\text{if } ~~ y=0 \end{cases}~~~~~~\text{注意底数是} e,不是2 \end{aligned} $$
将其合并为一个式子为: $$ \begin{aligned} \operatorname{Cost}\left(h_{\theta}(x), y\right)=-y \log \left(h_{\theta}(x)\right)-(1-y) \log \left(1-h_{\theta}(x)\right) \end{aligned} $$
完整的线性回归代价函数公式如下:
$$ \begin{aligned} J(\theta)=-\frac{1}{m} \sum_{i=1}^{m}\left[y^{(i)} \log \left(h_{\theta}\left(x^{(i)}\right)\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right] \end{aligned} $$
对应的梯度下降公式为(详细推导公式):
$$ \begin{aligned} \theta_{j}:=\theta_{j}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)} \end{aligned} $$
向量化的实现为(向量化过程): $$ \begin{aligned} \theta:=\theta-\frac{\alpha}{m} X^{T}(g(X \theta)-\vec{y}) \end{aligned} $$
6.6 高级优化(Advanced Optimization)
除梯度下降法之外,其他使 $\theta$ 最优的算法有:
- 共轭梯度(Conjugate gradient)
- BFGS
- L-BFGS
上述算法的优点:
- 不需要手动选择学习率 $\alpha$
- 比梯度下降快
上述算法的缺点:
- 实现复杂
6.7 多分类问题:一对多(Multiclass Classification: One-vs-all)
对于多分类问题,只需要将每个类别分别进行一对多处理即可
为每一个类别 $i$ 训练一个逻辑回归模型 $h_\theta^{(i)}(x)$,用来预测 $y=i$ 的可能性,当需要预测新的输入 $x$ 时,使用所有的模型进行预测,选择概率最大的作为预测结果: $\max _{i} h_{\theta}^{(i)}(x)$
$$ \begin{aligned} h_{\theta}^{(i)}(x)=P(y=i | x ;~ \theta) \end{aligned} $$
例如,有如下三个类别
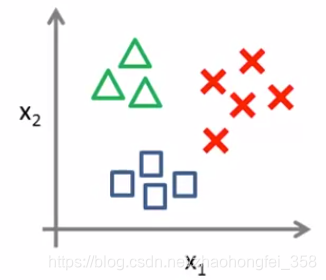
- 首先,将
X和口,看成一个类别,得到 $h_\theta^{(1)}(x)$
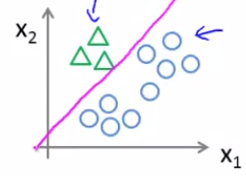
2. 然后,将 △ 和 X 看成一个类别,得到 $h_\theta^{(2)}(x)$
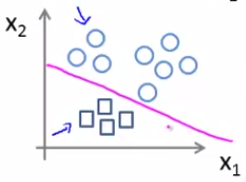
3. 最后,将 △ 和 口 看成一个类别,得到 $h_\theta^{(3)}(x)$
七、解决过拟合问题
7.1 过拟合问题
过拟合(Overfitting):如果我们特征太多(特征的高次方太多),那样学习的假设函数就可以非常好的拟合,但是却不能很好的进行泛化(预测新的输入)
Overfitting:If we have too many features, the learned hypothesis may fit the training set very well ( $J(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2} \approx 0$ ), but fail to generalize to new examples
过拟合:
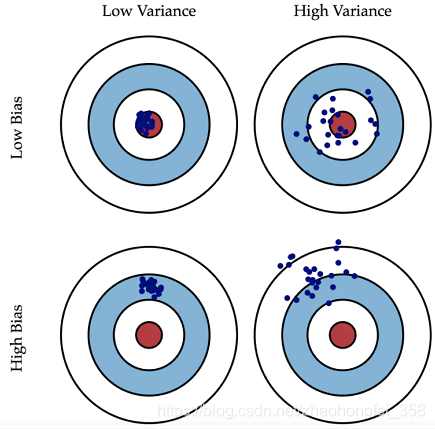
- 拟合的太好,不能很好泛化
- 高方差,低偏差
欠拟合:
- 拟合的不够好
- 低方差,高偏差
例如,我们有一个预测房价的模型:
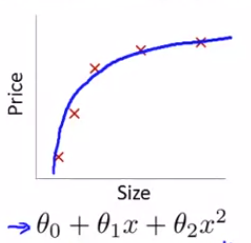
可以看出,这个假设刚刚好
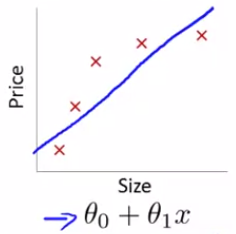
如果假设为直线,就会出现欠拟合(underfit) 问题,它会有较高的偏差(高偏差(High Bias)):
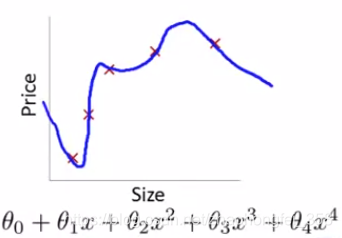
如果假设函数的特征太多,拟合的太好了,反而不好,称为过拟合(overfit),它会有较高的方差(高方差(High Variance)):
理解高偏差和高方差
逻辑回归的欠拟合和过拟合样例:
过拟合的处理:
- 减少特征的数量:①手动选择保留哪些特征 ②使用模型选择算法(Model selection algorithm)
- 正则化(Regularization):①保留所有特征,但是减少参数 $\theta_j$ 的量级(magnitude); 当特征比较多时,该方法就比较好了,因为每一个特征都为预测 $y$ 贡献了自己的一点力量
7.2 包含正则化的代价函数
正则化(Regularization)的目的:
- 防止过拟合
- 简化假设模型(“Simpler” hypothesis)
正则化的实现思路:为每个一 $\theta_j$ 增加一个惩罚,让每个 $\theta_j$ 都变小一点,这样最后的曲线就相对圆滑
正则化的代价函数公式:
$$ \begin{aligned} J(\theta)=\frac{1}{2 m}\left[\sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2}+\lambda \sum_{j=1}^{n} \theta_{j}^{2}\right] \end{aligned} $$
其中 $\lambda$ 被称为正则化参数(Regularization Paramter) 是一个常数
注意:正则化是从 $\theta_1$ 开始,因为 $\theta_0$ 是截距,不用参与正则化
$\lambda$ 不能过大,如果过大,对每一个 $\theta_j$ 的惩罚太大,最后他们全成0了,最后就会欠拟合,例如:
7.3 正则化的线性回归(Regularized Linear Regression)
正则化的代价函数公式:
$$ \begin{aligned} J(\theta)=\frac{1}{2 m}\left[\sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2}+\lambda \sum_{j=1}^{n} \theta_{j}^{2}\right] \end{aligned} $$
无正则化的梯度下降公式: $$ \begin{aligned} &Repeat ~~\{ \\ & ~~~~~~~\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)} \\ &\} \\\\ \end{aligned} $$
正则化后的梯度下降公式: $$ \begin{aligned} &Repeat ~~\{ \\ & ~~~~~~~\theta_j := \theta_j - \alpha \left[ \frac{1}{m} \sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)} +\frac{\lambda}{m} \theta_j \right] \\ &\} \\\\ \end{aligned} $$
整理后得: $$ \begin{aligned} \theta_{j}:=\theta_{j}\left(1-\alpha \frac{\lambda}{m}\right)-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)} \end{aligned} $$
要保证 $\left(1-\alpha \frac{\lambda}{m}\right)$ < 1,这样才能起到惩罚的作用,每次让 $\theta_j$ 减少的更多一点
无正则化的线性回归正规方程解:
$$ \begin{aligned} \theta = (X^T X)^{-1} X^Ty \end{aligned} $$
正则化后的线性回归正规方程解: $$ \begin{aligned} \theta=\left(X^{T} X+\lambda\left[\begin{array}{llll} 0 & & & \\ & 1 & & \\ & & 1 & & \\ & & & \ddots & \\ & & & & 1\\ \end{array}\right]\right)^{-1} X^{T} y \end{aligned} $$
7.4 正则化的逻辑回归(Regularized Logistic Regression)
正则化后的逻辑回归的代价函数为:
$$ \begin{aligned} J(\theta)=-\frac{1}{m} \sum_{i=1}^{m}\left[y^{(i)} \log \left(h_{\theta}\left(x^{(i)}\right)\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right] + \frac{\lambda}{2m} \sum_{j=1}^n \theta_j^2 \end{aligned} $$
无正则化的逻辑回归的梯度下降公式:
$$ \begin{aligned} \theta_{j}:=\theta_{j}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)} \end{aligned} $$
正则化后的逻辑回归的梯度下降公式:
$$ \begin{aligned} \theta_{j}:=\theta_{j}-\alpha \left[ \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)} + \frac{\lambda}{m} \theta_j \right] \end{aligned} $$
八、神经网络(Neural Networks)
8.1 非线性假设(Non-linear Hypotheses)
线性假设的弊端:特征太多了
假设现在预测房价模型:

使用逻辑回归模型,假设函数为右侧。我们有两个特征 $x_1 , x_2$,模型特征却有 $x_1,x_2,x_1x_2,...$ 无数个。
如果有100个特征,次方弄到2,那么最终的模型特征数量就总共有5150个特征,分别是 $x_1, x_2, \cdots, x_{100}, x_1^2, x_1x_2, \cdots,x_1x_{100},x_2^2,x_2x_3,\cdots,x_2x_{100},\cdots,x_{100}^2$
如果有100个特征,次方弄到3,最终会约有17w个模型特征。
所以,要提出非线性的模型假设
8.2 神经和大脑(Neurons and the Brain)
科普,可略
8.3 模型表示(Model Representation)
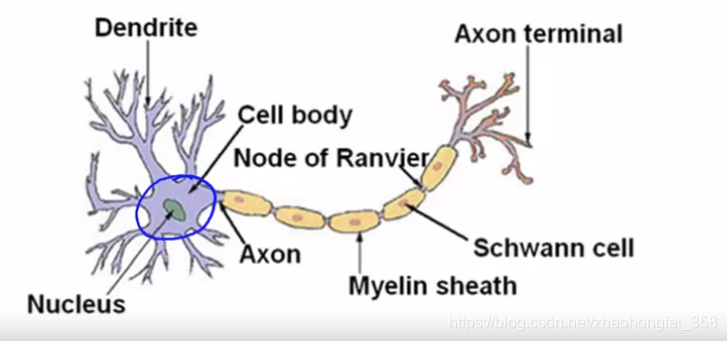
Dendrite(树突): 从树突输入数据
Nucleus(细胞核):由细胞核处理数据
Axon(轴突):通过轴突输出处理结果,或将处理结果反馈到下一层继续处理
神经网是以上述为思路构建的。
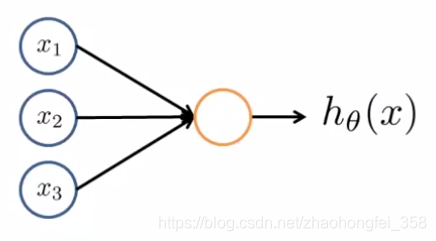
神经元模型(Neuron Model):
- $x_1, x_2, x_3$: 输入的特征值。$x_1$上面还有一个 $x_0$,称为偏置单元(Bias Unit),恒等于1。
- 激活函数(activation function):橙色的圈为激活函数,一般选用Sigmoid函数
- $h_\theta (x)$:模型的输出
- 权重(weight):$x_1$ 到
激活函数之间的那条线,也就是 $\theta_j$,在神经网络中,称为权重(weight)
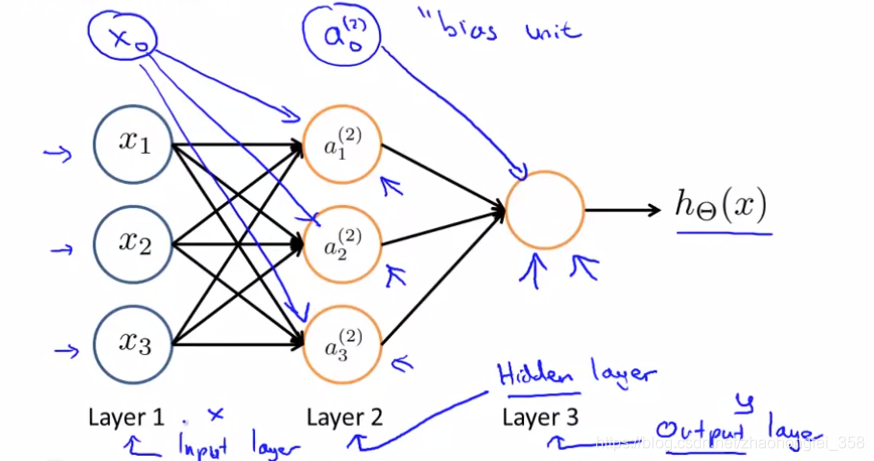
神经网络可以有多层,分别为:
- 输入层(Input Layer):Layer 1,数据从该层输入
- 隐藏层(Hidden Layer):Layer 2 到 Layer L-1,(L为层数),在第二层到最后一层之间的层称为隐藏层。隐藏层的每一个结点都是一个激活函数
- 输出层(Output Layer):Layer L,最后一层,该层得到的结果为输出结果
符号表示:
- $a_i^{(j)}$ : 在第 $j$ 层的第 $i$ 个激活单元
- $\Theta^{(j)}$:控制从 $j$ 层 到 $j+1$ 层函数映射的矩阵的权重矩阵。$\Theta^{(j)}$ 的维数:如果神经网络的 $j$层有 $s_j$ 个单元(units),$j+1$ 层有 $s_{j+1}$ 个单元,那么 $\Theta^{(j)}$ 是 $s_{j+1} \times (s_j + 1)$ 维的
- $\Theta^{(j)}_{k,i}$:第 $j$ 层,第 $k$ 个结点的第 $i$ 个权重的值
神经网络的向量化: $$ \begin{aligned} 令 ~~~~x=\left[\begin{array}{c} x_{0} \\ x_{1} \\ \cdots \\ x_{n} \end{array}\right]~~~~~ z^{(j)}=\left[\begin{array}{c} z_{1}^{(j)} \\ z_{2}^{(j)} \\ \cdots \\ z_{n}^{(j)} \end{array}\right] \end{aligned} $$
则有: $$ \begin{aligned} z^{(j)} & =\Theta^{(j-1)} a^{(j-1)} \\\\ a^{(j)} &= g(z^{(j)}) \\\\ h_{\Theta}(x) &=a^{(j+1)}=g\left(z^{(j+1)}\right) \end{aligned} $$
例如,对于上面的神经网络,有: $$ \begin{aligned} a_{1}^{(2)} &=g\left(\Theta_{10}^{(1)} x_{0}+\Theta_{11}^{(1)} x_{1}+\Theta_{12}^{(1)} x_{2}+\Theta_{13}^{(1)} x_{3}\right) \\\\ a_{2}^{(2)} &=g\left(\Theta_{20}^{(1)} x_{0}+\Theta_{21}^{(1)} x_{1}+\Theta_{22}^{(1)} x_{2}+\Theta_{23}^{(1)} x_{3}\right) \\\\ a_{3}^{(2)} &=g\left(\Theta_{30}^{(1)} x_{0}+\Theta_{31}^{(1)} x_{1}+\Theta_{32}^{(1)} x_{2}+\Theta_{33}^{(1)} x_{3}\right) \\\\ h_{\Theta}(x) &=a_{1}^{(3)}=g\left(\Theta_{10}^{(2)} a_{0}^{(2)}+\Theta_{11}^{(2)} a_{1}^{(2)}+\Theta_{12}^{(2)} a_{2}^{(2)}+\Theta_{13}^{(2)} a_{3}^{(2)}\right) \end{aligned} $$
将其向量化,可以表示为如下: $$ \begin{aligned} z^{(2)} & = \Theta^{(1)} x = \Theta^{(1)} a^{(1)} \\\\ a^{(2)} & = g(z^{(2)}) \\ \end{aligned} ~~~~~~~其中~~ x=\left[\begin{array}{l} x_{0} \\ x_{1} \\ x_{2} \\ x_{3} \end{array}\right] \quad~~ z^{(2)}=\left[\begin{array}{c} z_{1}^{(2)} \\\\ z_{2}^{(2)} \\\\ z_{3}^{(2)} \end{array}\right] $$
第三层为: $$ \begin{aligned} & 增加偏置节点 ~~~a_0^{(2)} = 1\\\\ & z^{3} = \Theta^{(2)}a^{(2)}\\\\ & h_\Theta(x) = a^{(3)} = g(z^{(3)}) \end{aligned} $$
8.4 样例1(Examples and Intuitions)
假设,我们要构建模型来预测 $~~~~~~y = x_1~ \text{AND}~ x_2~~~~~~~~~$ (1&1 = 1, 0&1 = 0, 0&0=0)
我们可以构架纳入下神经网络:
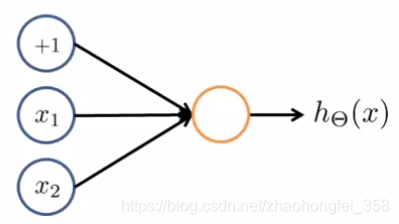
通过机器学习,我们得到了 $\Theta^{(1)} =(-30, +20, +20)^T$,即:
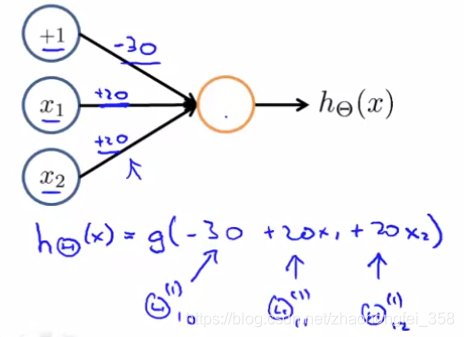
将 $x_1, x_2$ 代入 sigmoid 函数,可得:
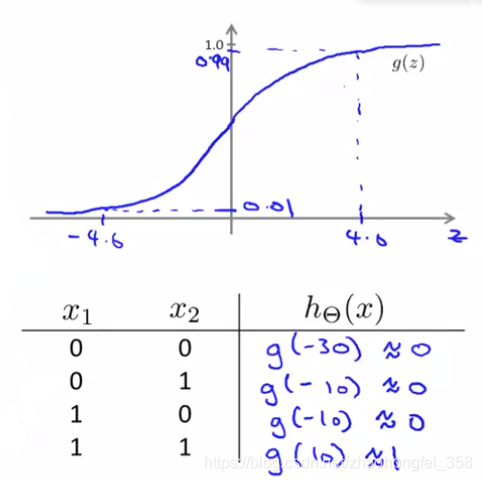
可以看出,我们预测的模型是正确的,可以满足一开始的预期 $y = x_1~ \text{AND}~ x_2$
同理,也可以构建 OR Function 的神经网络模型,如下:

8.5 多分类问题(Multiclass Classification)
上述例子为二分类问题,这样输出 $y \in \{0,1\}$,这样只需要用一个输出结点即可。
如果是一对多问题,例如:

我们需要将图片分成如下4个类别,则相应神经网络的输出结点应该是4个:

$$
\begin{aligned}
&\text { 当为Pedestrian时: } h_{\Theta}(x) \approx\left[\begin{array}{l}
1 \\
0 \\
0 \\
0
\end{array}\right],~~~ \text { 当为Car时:}h_{\Theta}(x) \approx\left[\begin{array}{l}
0 \\
1 \\
0 \\
0
\end{array}\right], \text { 当为Motorcycle时:} h_{\Theta}(x) \approx\left[\begin{array}{l}
0 \\
0 \\
1 \\
0
\end{array}\right], \text { etc. }\\
\end{aligned}
$$
九、神经网络(二)
9.1 代价函数
数学符号表示, 例如有这样一个神经网络:

- $L =$ 神经网络的层数。在上图中 $L=4$
- $s_l =$ $l$ 层的结点个数(不计算偏置节点(bias unit))。上图中,$s_1=3,s_2=s_3=5,s_4=s_L=4$
- $K$ = 多分类问题的类别数量。输出维度为 $y\in \mathbb{R}^K$ 。如果是二分类问题,结果为0,1,此时$y\in \{0,1\}$
逻辑回归的代价函数如下:
$$ \begin{aligned} J(\theta)=-\frac{1}{m}\left[\sum_{i=1}^{m} y^{(i)} \log h_{\theta}\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right]+\frac{\lambda}{2 m} \sum_{j=1}^{n} \theta_{j}^{2} \end{aligned} $$
神经网络的代价函数如下:
$$ \begin{aligned} J(\Theta)= & -\frac{1}{m}\left[\sum_{i=1}^{m} \sum_{k=1}^{K} y_{k}^{(i)} \log \left(h_{\Theta}\left(x^{(i)}\right)\right)_{k}+\left(1-y_{k}^{(i)}\right) \log \left(1-\left(h_{\Theta}\left(x^{(i)}\right)\right)_{k}\right)\right] \\\\ &+\frac{\lambda}{2 m} \sum_{l=1}^{L-1} \sum_{i=1}^{s_{l}} \sum_{j=1}^{s_{l+1}}\left(\Theta_{j i}^{(l)}\right)^{2} \end{aligned} $$ 其中: $$ \begin{aligned} h_{\Theta}(x) \in \mathbb{R}^{K} \quad\left(h_{\Theta}(x)\right)_{k}=k^{t h} \text { output } (第k个类别的输出值)\\ \end{aligned} $$
注意:$\sum_{i=1}^{s_{l}} \sum_{j=1}^{s_{l+1}}$ 分别是 $S_l$ 和 $S_{l+1}$ ,而不是 $sl$ 和 $s_l +1$
公式解释:
- 上半部分和逻辑回归类似,但不一样的地方在 $\sum_{k=1}^{K}$ 。在逻辑回归的二分类中,$y \in \{0,1\}$,其中 $\log h_{\theta}\left(x^{(i)}\right)$ 计算 $y=1$ 的部分,$\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)$计算 $y=0$ 的部分。而在多分类问题,$y\in \mathbb{R}^K$, 也就是有K个 $\{0,1\}$,这样在计算代价函数时,要把这 $K$ 种结果求和
- 下半部分是参数正则化。对于逻辑回归,只有 $n$ 个 $\theta_j$ 需要进行正则化。但在神经网络中就多了,因为有 $L$ 层,所以需要遍历 $1$ 到 $L-1$ 层(最后一层为输出层,所以就没有线($\theta$)了),所以就有了$\sum_{l=1}^{L-1}$ 。 对于 $l$层,因为有 $s_l$ 个结点(不算偏置结点),所以就有了 $\sum_{i=1}^{s_{l}}$ 。 而 $l$ 层的每一个结点都要与它的下一层($s_{l+1}$层)结点连条线(每条线代表一个$\Theta_{ji}^{(l)}$ 权重),所以就有了$\sum_{j=1}^{s_{l+1}}$
9.2 反向传播算法(Backpropagation Algorithm)
反向传播算法的用途:计算出 $\Theta$
与其他算法一致,我们得到了代价函数 $J(\Theta)$,目标是最小化 $J(\Theta)$,即
$$\begin{aligned}\min _{\Theta} J(\Theta)\end{aligned}$$
所以需要编码来计算:
- $J(\Theta)$
- $\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)$
正向传播算法的用途:给定权重 $\Theta$ 和 输入$x$,求出输出 $h_\Theta(x)$
正向传播算法思路:从输入层开始,一层一层计算,最终得出输出结果
例如,对于该神经网络,使用正向传播算法计算 $h_\Theta(x)$ 的过程如下:
$$ \begin{aligned} a^{(1)} &=x \\ z^{(2)} &=\Theta^{(1)} a^{(1)} \\ a^{(2)} &=g\left(z^{(2)}\right) \quad\left(\operatorname{add} a_{0}^{(2)}\right) \\ z^{(3)} &=\Theta^{(2)} a^{(2)} \\ a^{(3)} &=g\left(z^{(3)}\right)\left(\operatorname{add} a_{0}^{(3)}\right) \\ z^{(4)} &=\Theta^{(3)} a^{(3)} \\ a^{(4)} &=h_{\Theta}(x)=g\left(z^{(4)}\right) \end{aligned} $$
以 $a^{(4)}$ 为例,将其展开:
$$ \begin{aligned} a^{(4)}=g\left(z^{(4)}\right)=g\left(\Theta^{(3)} a^{(3)}\right)=g\left(\left[\begin{array}{l} \Theta_{10}^{(3)} a_{0}^{(3)}+\Theta_{11}^{(3)} a_{1}^{(3)}+\cdots+\Theta_{15}^{(3)} a_{5}^{(3)} \\\\ \Theta_{20}^{(3)} a_{0}^{(3)}+\Theta_{21}^{(3)} a_{1}^{(3)}+\cdots+\Theta_{25}^{(3)} a_{5}^{(3)} \\\\ \Theta_{30}^{(3)} a_{0}^{(3)}+\Theta_{31}^{(3)} a_{1}^{(3)}+\cdots+\Theta_{35}^{(3)} a_{5}^{(3)} \\\\ \Theta_{40}^{(3)} a_{0}^{(3)}+\Theta_{41}^{(3)} a_{1}^{(3)}+\cdots+\Theta_{45}^{(3)} a_{5}^{(3)} \end{array}\right]\right) \end{aligned} $$
反向传播算法思路:
例如,对于该神经网络,首先,令:
- $\delta_j^{(l)}=$ $l$ 层结点 $j$ 的“误差(error)”
- $\delta^{(l)} = (\delta^{(l)}_1, \delta^{(l)}_2, \cdots, \delta^{(l)}_n)^T$ ,其中n代表该层的结点数
则有:
$$ \begin{aligned} &\delta^{(4)} = a^{(4)} - y = h_\Theta(x) -y \\ &\delta^{(3)}=\left(\Theta^{(3)}\right)^{T} \delta^{(4)} ~.* g^{\prime}\left(z^{(3)}\right) = \left(\Theta^{(3)}\right)^{T} \delta^{(4)} ~.*\left(a^{(3)}~. * (1-a^{(3)})\right) \\ &\delta^{(2)}=\left(\Theta^{(2)}\right)^{T} \delta^{(3)} ~.* g^{\prime}\left(z^{(2)}\right) = \delta^{(2)}=\left(\Theta^{(2)}\right)^{T} \delta^{(3)} ~.* \left(a^{(2)}~. * (1-a^{(2)})\right) \end{aligned} $$
其中 $~. *$ 是指两矩阵的对应元素相乘
反向传播算法伪代码:
$\text { Training set }\left\{\left(x^{(1)}, y^{(1)}\right), \ldots,\left(x^{(m)}, y^{(m)}\right)\right\}$
$\text { Set } \left.\Delta_{i j}^{(l)}=0 \text { (for all } l, i, j\right)$
$\text { For } i=1 \text { to } m$
$~~~~~\text { Set } a^{(1)}=x^{(i)}$
$~~~~~\text { Perform forward propagation to compute } a^{(l)} \text { for } l=2,3, \ldots, L$
$~~~~~\text { Using } y^{(i)}, \text { compute } \delta^{(L)}=a^{(L)}-y^{(i)}$
$~~~~~\text { Compute } \delta^{(L-1)}, \delta^{(L-2)}, \ldots, \delta^{(2)}$
$~~~~~\Delta_{i j}^{(l)}:=\Delta_{i j}^{(l)}+a_{j}^{(l)} \delta_{i}^{(l+1)}$
$D_{i j}^{(l)}:=\frac{1}{m} \Delta_{i j}^{(l)}+\lambda \Theta_{i j}^{(l)}~~~ \text { if } j \neq 0$
$D_{i j}^{(l)}:=\frac{1}{m} \Delta_{i j}^{(l)} \quad~~~~~~~~~~~~~ \text { if } j=0$
最终得: $$\begin{aligned}\frac{\partial}{\partial \Theta_{i j}^{(l)}} J(\Theta)=D_{i j}^{(l)}\end{aligned}$$
9.5 梯度检测
梯度检测:检测自己的梯度下降代码写的是否正确
思想:求出该点斜率(导数)的近似值,然后与实际值比较,如果差的多,说明求导公式有问题。
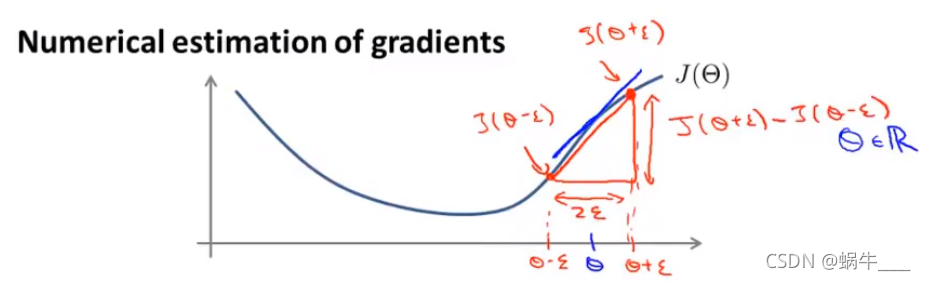
对于某一个 $\theta$ 有: $$ \begin{aligned} \frac{d}{d \theta} J(\theta) \approx \frac{J(\theta+\varepsilon)-J(\theta-\varepsilon)}{2 \varepsilon} \end{aligned} $$
其中 $\varepsilon$ 为一个非常小的值,比如可以取 $\varepsilon=10^{-4}$
对于 向量$\theta$, 有:
$$ \begin{aligned} &\left.\theta \in \mathbb{R}^{n} \quad \text { (E.g. } \theta \text { is "unrolled" version of } \Theta^{(1)}, \Theta^{(2)}, \Theta^{(3)}\right) \\\\ &\theta=\theta_{1}, \theta_{2}, \theta_{3}, \ldots, \theta_{n} \\\\ &\frac{\partial}{\partial \theta_{1}} J(\theta) \approx \frac{J\left(\theta_{1}+\epsilon, \theta_{2}, \theta_{3}, \ldots, \theta_{n}\right)-J\left(\theta_{1}-\epsilon, \theta_{2}, \theta_{3}, \ldots, \theta_{n}\right)}{2 \epsilon} \\\\ &\frac{\partial}{\partial \theta_{2}} J(\theta) \approx \frac{J\left(\theta_{1}, \theta_{2}+\epsilon, \theta_{3}, \ldots, \theta_{n}\right)-J\left(\theta_{1}, \theta_{2}-\epsilon, \theta_{3}, \ldots, \theta_{n}\right)}{2 \epsilon} \\\\ &\cdots \\\\ &\frac{\partial}{\partial \theta_{n}} J(\theta) \approx \frac{J\left(\theta_{1}, \theta_{2}, \theta_{3}, \ldots, \theta_{n}+\epsilon\right)-J\left(\theta_{1}, \theta_{2}, \theta_{3}, \ldots, \theta_{n}-\epsilon\right)}{2 \epsilon} \end{aligned} $$
9.6 随机初始化
对于 $\Theta$ 的初始化,有两个注意点:
- 不能将 $\Theta^{(l)}_{ij}$ 初始化为0
- 建议将每一个 $\Theta^{(l)}_{ij}$ 初始化为范围在 $[-\varepsilon, \varepsilon]$ 中的随机数
9.7 神经网路总结
训练一各神经网络分为以下几步: 1. 随机初始化权重($\Theta$) 2. 对于每一个 $x^{(i)}$,使用正向传播获得 $h_{\Theta}\left(x^{(i)}\right)$ 3. 使用代码计算 $J(\Theta)$ 4. 使用反向传播计算偏导数 $\frac{\partial}{\partial \Theta_{j k}^{(l)}} J(\Theta)$ 5. 使用“梯度检测”来比较使用反向传播计算出的 $J(\Theta)$ 和 估算的$J(\Theta)$,来判断代码是否有问题。如果没问题,注释掉梯度检测这段代码 6. 使用梯度下降或其他高级优化方法最小化 $J(\Theta)$,最终得到 $\Theta$

