【论文解读】(CSC任务的音标和字形信息到底用了多少?)Investigating Glyph-Phonetic Information for Chinese Spell Checking

文章目录
- 相关信息
- Abstract(摘要)
- 1. 介绍(Introduction)
- 2. 相关工作(Related Work)
- 3. 实验一:探究Glyph-Phonetic信息(Experiment-I: Probing for Character Glyph-Phonetic Information)
- 4. 实验2:探究错字修正(Experiment-II: Probing for Homonym Correction)
- 4.1 CCCR: Correction with Misspelled Character Coverage Ratio
- 4.2 Correction Setting Results
- 4.3 Isolation Correction Setting Experiment
- 4.4 Results and Analysis
- 5. 结论(Conclusion)
- 6. 局限性(Limitation)
- 本文缩写表
相关信息
年份:2022年12月
论文地址:https://arxiv.org/abs/2212.04068
论文代码:https://github.com/piglaker/ConfusionCluster
论文阅读前提:需要了解中文拼写检查任务(CSC)
Abstract(摘要)
许多中文拼写检查(Chiniese Spell Checking, CSC)模型都使用了“字形信息+拼音信息”(glyph-phonetic)来进行预测,但是“这些glyph-phonetic信息到底被用了多少”是不清楚的,所以作者提出了两个新的方法来验证,同时也可以提升模型的泛化能力。
1. 介绍(Introduction)
作者这篇论文主要回答了两个问题:
- Q1:现有的中文预训练模型(Chinese pre-trained models)编码了glyph-phonetic信息了吗?
- Q2:现有的CSC模型在做预测时,是否完全利用了错字的glyph-phonetic信息呢?
作者针对这两个问题,提出了三个贡献(两个Probe task和一个setting),如下:
- 作者提出了一个简单的probe task来度量中文预训练模型包含的glyph-phonetic信息。
- 作者提出了一个“错字修正覆盖率(Correction with Misspelled character Coverage Ratio, CCCR)”指标来衡量一个CSC模型在做预测时,到底用了多少错字信息。该指标也可以解释为什么现在的CSC方法在数据集上表现很好,但在实践中却很差。
- 作者为CSC任务提出了一个新的setting,名为“isolation correction”,其能更好的检验CSC模型的泛化能力和修正能力。
2. 相关工作(Related Work)
略
3. 实验一:探究Glyph-Phonetic信息(Experiment-I: Probing for Character Glyph-Phonetic Information)
在第一章介绍章节,作者说回答了两个问题,第一个问题是:“现有的中文预训练模型(Chinese pre-trained models)编码了glyph-phonetic信息了吗?”
作者提出的一个贡献是:作者提出了一个简单的probe task来度量中文预训练模型包含的glyph-phonetic信息。
本章就是作者针对该问题所提出的probe task进行详细说明。
作者提出的方法:
作者分别对字形(Glyph)信息和拼音(Phonetic Probe)信息进行探究,其思路几乎一致。
以拼音信息为例,作者首先构造一个数据集,其一个sample由两个字组成。对于其Label,拼音一样,则label为1,否则label为0。例如,(程, 称)=1, (产, 称)=0。
然后作者使用预训练模型对字进行编码,然后将编码后的两个字向量concat到一起,然后经过一个简单的多层感知机(Multilayer Perceptron,MLP)进行二分类的预测。
假设MLP经过训练后可以成功预测这俩字是否拼音一样,说明预训练模型对字编码时包含其拼音信息,否则就不包含。(训练MLP时,最前面的预训练模型参数是要固定不变的)
3.1 Glyph Probe
本节详细介绍了作者对于字形信息的探究方法。
数据集的构造:
数据集样本示例如下:

如图所示,一个样本由两个字组成,其Label是1或0。1表示这俩字相似,0表示不相似。具体定义为: 如果两个字是包含被包含的关系时,其Label是1,否则Label是0。
作者具体构造数据集的方法如下:
- 预处理阶段,作者选择BERT中出现的汉字,并去除掉一些生僻字,例如“圜”等。 全量汉字记为 $\mathcal{W}=\left\{w_1, w_2, \ldots, w_d\right\}$,$d$ 是汉字的数量。
- 对于一个字 $w$,作者使用hanzi_chanzi工具将其拆开,例如“称”字会被拆成“禾”和“尔”。 记为:$\mathcal{U}=\left\{u_1, u_2, \ldots, u_c\right\}$,其中 $c$ 是所有的偏旁部首数量。
- 如果 $u_i$ 是 $w_i$ 的一部分,那么 $u_i, w_i$ 就是一对儿正样本,反之则是负样本。
- 按3的方法,就能构造出正样本集合 $\mathcal{D}_{pos}=\left\{\left\{u_1, w_1\right\},\left\{u_2, w_1\right\}, \ldots,\left\{u_i, w_d\right\}\right\}$
- 同样,也可以构造出负样本集合 $\mathcal{D}_{neg}=\left\{\left\{u_1^n, w_1\right\},\left\{u_2^n, w_1\right\}, \ldots,\left\{u_i^n, w_d\right\}\right\}$, 其中 $d$ 和正样本中的 $d$ 一致,$u^n$ 是从偏旁部首集合中随机选择的。
- 最终按8:2进行训练集和测试集的拆分
构造数据集后,就是具体方法:
- 首先,作者将样本 $i$(两个字)通过预训练模型得到两个embedding,然后将两个embedding连接(concat)到一起,得到模型的输入 $x_i$
该embedding是不包含上下文信息的。
- 使用多层感知机进行前向传播,最后经过Sigmoid得到最终预测结果 $\hat{y_i}$ ,用公式表示为:$\hat{y}_i=\operatorname{Sigmoid}\left(\operatorname{MLP}\left(x_i\right)\right)$
3.2 Phonetic Probe
拼音信息的探究方法与字形几乎一致,只是数据集些许不一样而已。
拼音信息的数据集构造方法:

同样,一个样本包含两个字,其Label为1或0。当两个字拼音相同时(忽略声调),label为1,否则label为0。
数据集构造方法(与字形数据集构造也类似):
- 对于字典 $W$ 中的字 $w_i$ ,我们从字典中找到另一个与其拼音相同的 $u_i$,然后将 $(u_i, w_i)$ 作为正样本
- 类似1,我们从字典中找一个与 $w_i$ 拼音不相同的,将 $(s_i, w_i)$ 作为负样本
3.3 结果与分析(Results and Analysis)
作者使用多个预训练模型进行了实验,结果如下图:

Control是完全随机初始化的embedding模型。
从结果可以得出以下结论:
- 随机模型(control)没有任何编码Glyph信息和Phonetic信息的能力(预测准确率接近50%)。
- 几乎所有BERT模型的都具有一定的编码Glyph信息的能力,但不多,差不多准确率都在75%,比word2vec强一点。
- 除ChineseBERT外,这些模型几乎没有编码Phonetic信息的能力(预测准确率都在55%左右)。
- ChineseBERT编码Phonetic信息的能力比他们稍微强一点,作者认为可能是因为在最开始ChineseBERT设计时就将Phonetic信息考虑在内。(ChineseBERT可以参考这篇博文)
4. 实验2:探究错字修正(Experiment-II: Probing for Homonym Correction)
本章是回答作者提出的问题二:现有的CSC模型在做预测时,是否完全利用了错字的glyph-phonetic信息呢?
对应作者的贡献2:作者提出了一个“错字修正覆盖率(Correction with Misspelled character Coverage Ratio, CCCR)”指标来衡量一个CSC模型在做预测时,到底用了多少错字信息。
本章作者提出了“错字修正覆盖率(CCCR)”的概念,CCCR越高,说明CSC模型在做预测时,更多的参考了“错字”。按原文的说法就是:CCCR可以知道模型在做出预测时是否调整了预测概率分布。
“调整预测概率分布”在后续会给出解释。这里简单举例说明:假设句子为 “我要去贝你奶奶”。如果模型没有参考错字“贝”时,预测的概率分布可能是“接(0.65), 找(0.25), 见(0.1)”。但如果模型参考了错字“贝”,则预测的概率分布可能就变为“见(0.95), 接(0.06), 找(0.04)”
4.1 CCCR: Correction with Misspelled Character Coverage Ratio
CCCR描述的是能根据错字修正句子所占的比例。即:
CCCR用我自己的语言描述为:
$$ \begin{aligned} CCCR= \frac{模型能够根据错字提醒改正的句子数}{需根据错字提醒才能改正的句子数} \end{aligned} $$
需根据错字提醒才能改正的句子(论文中为“MLM集合”):有些句子必须根据错字提醒才能正确改正,例如:“我要去[MASK]我奶奶”,这里的[MASK]填“接、见、找、等”都行。这种属于该集合中的句子。 同理,有些句子就算不提醒也知道填啥,例如“[MASK]你太美”,这没有歧义,[MASK]肯定填“鸡”,这种句子就不在该集合中。
模型能够根据错字提醒改正的句子:对于错字位置有歧义的句子,如果模型能够根据错字改正该句子,那么该句子就属于该集合。 例如:“我要去贝我奶奶”,模型成功的将“贝”改为了“见”,那么该集合数量+1。
上面若没看懂,可以看如下例子,例如:我们有5个需修改的句子
- 我要去
贝我奶奶。 (有歧义,不看“贝”不知道该填见) 集你太美。 (无歧义,不看也知道填鸡)- 你是不是有
饼。(有歧义,不看饼不知道填病) - 此生无悔入华
虾。(无歧义,不看也知道填夏) - 我喜欢吃
礼。(有歧义,不看礼,不知道填梨)
上述有3个句子是有歧义句子,所以 $\text{需根据错字提醒才能改正的句子}=3$
此时,我们将这5个句子送给CSC模型进行预测(不关心那2个无歧义的句子),假设最终对有歧义的3个句子成功预测对了2个,那么 $\text{模型能够根据错字提醒改正的句子数}=2$。
最终:$CCCR=\frac{2}{3}$
在论文原文中,“需根据错字提醒才能改正的句子”集合为记为 $MLM$, “模型能够根据错字提醒改正的句子”集合记为 $Homonym$ 。
对于$MLM$集合的构造,作者使用的方法是:使用MLM任务来预测错字,若能成功出正确的字,则该句子“不属于”MLM集合,否则就属于。 例如,①对于句子 “我要去贝我奶奶”,使用MLM任务,就将原句子变为“我要去[MASK]我奶奶”,此时模型无法预测出“见”字,所以该句子属于MLM集合元素。 ②对于句子“此生无悔入华虾”,使用MLM任务,将原句子变为“此生无悔入华[MASK]”,此时模型成功预测出“夏”字,所以该句子不属于MLM集合元素。
Homonym集合构造方法:若一个句子属于MLM集合,且模型成功预测出正确字,那么该句子就属于$Homonym$集合元素。 (TODO,这里好像有问题)
上述任务用论文中的图表示为:

论文中对CCCR过程给出了详细的数学公式描述(如果看懂上面,且不感兴趣可以跳过):
假定 $\mathcal{C}$ 是语言 $L$ 中所有有限长度句子$C_i$ 的集合。$\mathcal{C}=\left\{C_0, \ldots, C_i, \ldots\right\}, C_i=\left\{c_{i, 1}, \ldots, c_{i, n}, \ldots\right\}$,其中 $c_{i,j} \in L$
$L$ 指代的就是所有汉字。 $C_i$ 就是一个句子,$c_{i,j}$ 就是句子$C_i$ 中的一个字。 $\mathcal{C}$ 就是全体中文句子。
定义 $C_i^{n,a}=\left\{c_{i, 1}, \ldots, c_{i, n-1}, a, c_{i, n+1}, \ldots\right\}$,即句子$C_i$的位置 $n$ 是错字 $a$。
定义 $X_i$ 为一个输入样本,则对于样本 $X_i$,其 $i$ 位置的输出为:
$$ \begin{aligned} P\left(y_i=j \mid X_i, w\right)=\operatorname{softmax}\left(W H^w\left(X_i\right)+b\right)[j] \end{aligned} $$
例如 $X_i$ 为 “我要去贝我奶奶”,那么 $P(y_3=j|X_i,w)$ 就表示第3个字(贝字所在的位置)预测为“见”字的概率(见字在字典中的index为 $j$)
CCCR是由 $\mathcal{MLM}$ 和 $Homonym$ 两个集合组成,前者表示“需要错字信息才能被正确修复的样本”,后者表示“模型可以根据错字信息调整概率分布的样本(也就是可以正确修改的样本)”
定义 $\mathcal{D}$ 是 $\mathcal{C}$ 的一个子集,意思就是 $\mathcal{D}$ 是我们的数据集。
$\mathcal{MLM}$ 是 $\mathcal{D}$ 的子集,对于输入句子 $C_i \in \mathcal{D}$,$C_i = \left\{c_1, c_2,[M A S K], \ldots, c_T\right\}$,[mask]所在位置就是错字的位置。如果满足下面不等式,则 $C_i \in MLM$ :
$$ \begin{aligned} P\left(y_i=\text { noise } \mid C_i^{n, m a s k}, w\right)>P\left(y_i=Y_i \mid C_i^{n, \text { mask }}, w\right) \end{aligned} $$
该不等式中的符号为:$y_i=\text{noise}$ 表示预测结果是错误的(除了正确字,随便啥都行),$y_i=Y_i$ 表示预测结果是正确的。所以该不等式就表示,预测错字的概率比预测正确字的概率高。
例如:“我要去[MASK]我奶奶”中,对于[MASK]的预测概率分布为“接(0.65), 见(0.32), ...”,即$P(y_3=接)>P(y_3=见)$,那么该样本就属于MLM集合
$Homonym$ 与MLM类似,对于输入 $C_i=\left\{c_1, c_2, c_{\text {misspelled }}, \ldots, c_T\right\}$ (这次并没有讲错字改成[mask],而是采用原本的错字)。如果满足下面不等式,则 $C_i \in Homonym$ :
$$ \begin{aligned} \left.P\left(y_i=Y_i \mid C_i^{n, c_{\text {misspelled }}}, w\right)\right)>P\left(y_i=\text { noise } \mid C_i^{n, c_{\text {misspelled }}}, w\right) \end{aligned} $$
该不等式的意思与MLM不等试刚好相反,即正确字的概率比错字的概率大。
有了上述两个集合,那么CCCR的公式为:
$$ \begin{aligned} C C C R=\frac{\mid\left\{C_i \mid C_i \in M L M \wedge C_i \in \text { Homonym }\right\} \mid}{\left|\left\{C_i \mid C_i \in M L M\right\}\right|} \end{aligned} $$
|{}|表示求集合的元素个数,$\wedge$ 表示逻辑与
CCCR的baseline
作者还为CCCR设置了一个baseline,公式如下:
$$ \begin{gathered} \text { guess }_i=\frac{P\left(y_i=\text { noise } \mid C_i^{n, \text { mask }}, w\right)}{1-P\left(y_i=\text { noise } \mid C_i^{n, \text { mask }}, w\right)} \\\\ \text { CCCR }_{\text {baseline }}=\frac{\sum_{i \in S}\left\{1 * \text { guess }_i\right\}}{\left|\left\{C_i \mid C_i \in M L M\right\}\right|} \end{gathered} $$
TODO,这个Baseline公式没看懂
4.2 Correction Setting Results
TODO,这里作者应该暂时还漏了一个表。这个表应该大概是这样:经过SIGHAN训练集训练前,BERT模型表现一般,但训练后,SIGHAN模型表现较好。
作者认为,之所以训练后表现很好,并不是模型真的变好了,而是因为SIGHAN的训练集和测试集有很多重叠的部分。 所以模型并不是学会了如何改错,而是记住了训练集的内容。
4.3 Isolation Correction Setting Experiment
为了更好的衡量 4.2 中的问题,作者提出了一个新的setting,即“Isolation Correction”,其思路很简单:将SIGHAN训练集和测试集中重叠的部分删除掉,然后删除后的训练集训练模型和测试模型。
作者对SIGHAN重叠数据的处理情况如下表:
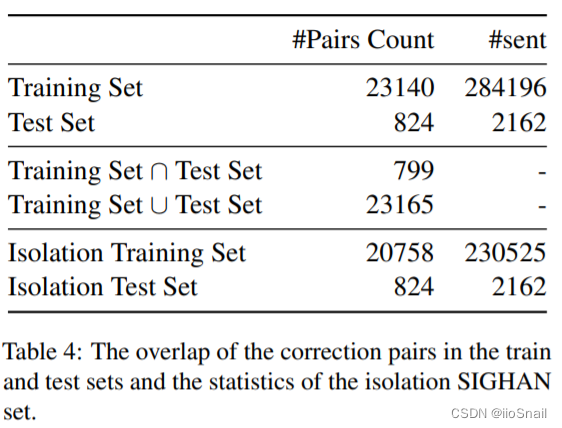
4.4 Results and Analysis
作者对几个BERT模型和两个CSC模型使用Isolation SIGHAN数据集进行训练和测试,结果如下表:
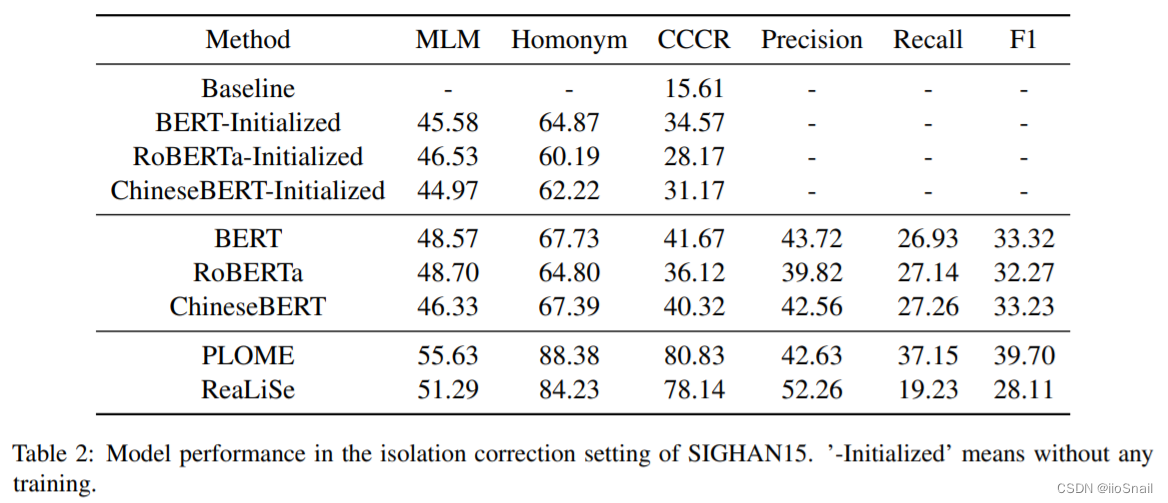
可以看到,F1一下子跌到没法看了。说明这些模型的泛化能力还是比较差的。
5. 结论(Conclusion)
作者根据实验分析,得出了以下结论:
- 目前的中文预训练语言模型(Chinese PLM)可以编码一部分Glyph信息,但几乎无法编码Phonetic信息
- 现有的CSC模型在做预测时,无法完全利用Glyph-phonetic信息。
- SIGHAN的训练集和测试集有大量重叠的部分,不利于校验CSC模型的泛化能力。,作者提出了另一个setting来校验模型泛化能力
6. 局限性(Limitation)
作者实验的局限性主要有两点:
- 之前的CSC模型大多都很难复现,所以作者只弄了两个。
- SIGHAN测试集小,数据质量差,涉及领域窄,其与真实场景差距大。
本文缩写表
- CSC: Chinese Spell Checking, 中文拼写检查
- PLM: Pre-trained Language Model,预训练语言模型,例如BERT
- MLP:Multilayer Perceptron,多层感知机。就是多层全连接神经网络。
- MLM:Masked-Language Modeling,预训练BERT时使用的任务,即将一个句子的一个字使用
[mask]给盖住,然后让BERT预测这个[mask]是什么字。

