【论文源码解读】(中文拼写检查, CSC)SCOPE:Improving Chinese Spelling Check by Character Pronunciation Prediction

论文信息
论文地址 :https://arxiv.org/pdf/2210.10996.pdf
论文年份:2022年10月
论文源码(官方) : https://github.com/jiahaozhenbang/SCOPE
阅读前提:熟悉CSC任务,要具备大概看一下模型架构图就能知道作者是怎么做的能力。
Hugging Face地址(非官方):https://huggingface.co/iioSnail/ChineseBERT-for-csc
论文的贡献与思路
- 在CSC任务的基础上,该论文又构建了一个辅助任务来进行拼音预测,这样就让模型的Encoder具备了编码拼音的能力。
- 针对上面这点,论文对辅助任务的损失进行调整。
- 作者提供了预训练的SCOPE模型,可供后续做迁移学习。
- 作者提出了CIC(约束迭代矫正)方法,解决了连续错字问题。
我将论文中的SCOPE预训练的ChineseBERT部分提取出来了,百度网盘链接:链接:https://pan.baidu.com/s/1bvcvplGdcF__8lTMIBt-FQ?pwd=9m2s 提取码:9m2s
论文提供的预训练模型在Sighan15Test上的结果如下:
Character-level Detect Acc: 0.9882, P: 0.7671, R: 0.6230, F1: 0.6876 Character-level Correct Acc: 0.9857, P: 0.7280, R: 0.5064, F1: 0.5973 Sentence-level Detect Acc: 0.7227, P: 0.8172, R: 0.5619, F1: 0.6659 Sentence-level Correct Acc: 0.6845, P: 0.7939, R: 0.4843, F1: 0.6016
在CSCD-IME Test上的结果如下:
Character-level Detect Acc: 0.9836, P: 0.2733, R: 0.5249, F1: 0.3594 Character-level Correct Acc: 0.9829, P: 0.2442, R: 0.4509, F1: 0.3168 Sentence-level Detect Acc: 0.4749, P: 0.4243, R: 0.3921, F1: 0.4076 Sentence-level Correct Acc: 0.4533, P: 0.3936, R: 0.3452, F1: 0.3678
模型架构
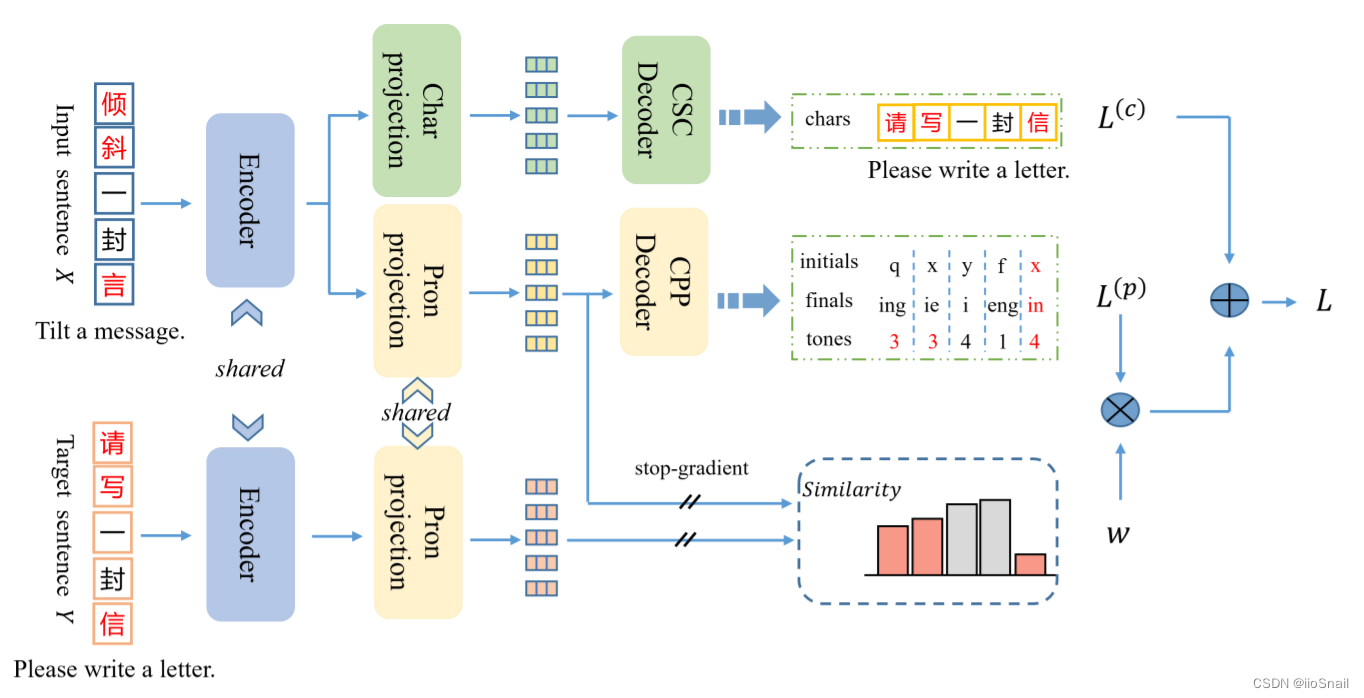
该模型架构比较容易理解,大致如下:
- CSC任务:使用Encoder(ChineseBERT)对正确句子进行编码,然后使用全连接层进行Token的预测,最后使用CrossEntropyLoss计算损失 $L^{(c)}$
- CPP(Chinese pronunciation prediction Decoder)任务:使用Encoder对正确句子进行编码,然后使用3个全连接层分别输出每个token的声母(initials)、韵母(finals)和声调(tones)的预测结果,然后使用CrossEntropy计算损失 $L^{(p)}$
- 调整CPP损失:对正确句子使用Encoder进行编码,然后使用一个Linear进行和正确句子相同的线性变化后得到错误句子每个token的embedding,然后每个token和正确句子对应token的embeddings计算相似度,得到权重,调整CPP损失。相似度越大,权重越高。
接下来对每个模块进行源码分析。
Encoder
Encoder使用的ChineseBERT,详情可见ChineseBERT解读
源码中对应:models/modeling_multitask.py第73行:
```python
class Dynamic_GlyceBertForMultiTask(BertPreTrainedModel):
def __init__(self, config):
super(Dynamic_GlyceBertForMultiTask, self).__init__(config)
self.bert = GlyceBertModel(config) # 这个就是ChineseBERT
self.cls = MultiTaskHeads(config)
self.loss_fct = CrossEntropyLoss()
self.init_weights()
```
Char Projection
是一个“Linear+GELU激活函数+LayerNorm”的组合
源码为:
```python
class BertPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
# 这里是配置激活函数的
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
```
这段源码是transformers框架中的,所在位置为:
transformers.models.bert.modeling_bert.py
CSC Decoder
在Char Projection步骤后,最后再用一个Linear层输出预测结果(未进行Softmax前的结果)。
源码为:
```python
class BertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config) # 这个就是Char Projection
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
```
同样这段源码也是transformers框架中的,所在位置为:
transformers.models.bert.modeling_bert.py作者的
Char Projection->Char Decoder本质就是使用了tranformers中的BertLMPredictionHead作为预测层。
CSC Task损失函数 $L^{(c)}$
CSC任务的损失函数比较传统,就是CrossEntropy。
对应源码为:
```python
class Dynamic_GlyceBertForMultiTask(BertPreTrainedModel):
def __init__(self, config):
super(Dynamic_GlyceBertForMultiTask, self).__init__(config)
self.bert = GlyceBertModel(config)
self.cls = MultiTaskHeads(config)
# 这里指定reduction='none'是因为后面会手动求平均
self.loss_fct = CrossEntropyLoss(reduction='none')
...
def forward(...):
...
# 对input_ids中的 pad(0), <bos>(101),<eos>(102) 进行mask,它们不需要计算loss
loss_mask = (input_ids != 0)*(input_ids != 101)*(input_ids != 102).long()
...
loss_fct = self.loss_fct
if labels is not None and pinyin_labels is not None:
# 将不需要计算loss的部分的label更新成-100(因为CrossEntropy默认忽略-100这个index)
# 然后使用CrossEntropyLoss计算CSC Task的loss
active_loss = loss_mask.view(-1) == 1
active_labels = torch.where(
active_loss, labels.view(-1), torch.tensor(loss_fct.ignore_index).type_as(labels)
)
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), active_labels)
...
def weighted_mean(weight, input):
return torch.sum(weight * input) / torch.sum(weight)
# 对CrossEntropyLoss求平均。这里的weight其实对CSC Task没什么用。
# 作者之所以这么写主要是用于对辅助任务(拼音预测)的。
masked_lm_loss = weighted_mean(torch.ones_like(masked_lm_loss), masked_lm_loss)
...
... # end if
...
```
Pron Projection
拼音映射层。和Char Projection使用的都是BertPredictionHeadTransform。
CPP Decoder
CPP Decoder (Chinese pronunciation prediction Decoder) 负责将Pron Projection编码好的特征预测成三种数据,分别为:
- 声母(initials):包含
'zh', 'ch', 'sh', 'b', 'p', 'm', 'f', 'd', 't', 'n', 'l', 'g', 'k', 'h', 'j', 'q', 'x', 'r', 'z', 'c', 's', 'y', 'w',共23个 - 韵母(finals): 包含
'a', 'ai', 'an', 'ang', 'ao', 'e', 'ei', 'en', 'eng', 'er', 'i', 'ia', 'ian', 'iang', 'iao', 'ie', 'in', 'ing', 'iong', 'iu', 'o', 'ong', 'ou', 'u', 'ua', 'uai', 'uan', 'uang', 'ue', 'ui', 'un', 'uo', 'v', 've',共34个 - 声调(tones): 包含
'1', '2', '3', '4', '5',即1-4声和无声。
例如对于鸡应该输出 j, i, 1。
因此,CPP Decoder有三个线性层。源码如下:
```python
class Phonetic_Classifier(nn.Module):
def __init__(self, config):
super().__init__()
self.pinyin=Pinyin()
self.transform = BertPredictionHeadTransform(config) # Pron Projection
# 声母分类器
self.sm_classifier=nn.Linear(config.hidden_size,self.pinyin.sm_size)
# 韵母分类器
self.ym_classifier=nn.Linear(config.hidden_size,self.pinyin.ym_size)
# 声调分类器
self.sd_classifier=nn.Linear(config.hidden_size,self.pinyin.sd_size)
def forward(self, sequence_output):
sequence_output = self.transform(sequence_output)
sm_scores = self.sm_classifier(sequence_output)
ym_scores = self.ym_classifier(sequence_output)
sd_scores = self.sd_classifier(sequence_output)
# 返回三种数据softmax前的数据
return sm_scores,ym_scores,sd_scores
```
CPP Task损失函数 $L^{(p)}$
由于CPP Decoder有三个输出(声母、韵母、声调),所以CPP Task需要对这三种分别计算Loss。最后再将Loss相加。
因为声母、韵母、声调都是多分类任务,所以同样采用CrossEntropy。
源码如下:
```python
class Dynamic_GlyceBertForMultiTask(BertPreTrainedModel):
def __init__(self, config):
super(Dynamic_GlyceBertForMultiTask, self).__init__(config)
self.bert = GlyceBertModel(config) # Encoder
self.cls = MultiTaskHeads(config) # Projection和Decoder
self.loss_fct = CrossEntropyLoss(reduction='none')
...
def forward(...):
...
# 对input_ids中的 pad(0), <bos>(101),<eos>(102) 进行mask,它们不需要计算loss
loss_mask = (input_ids != 0)*(input_ids != 101)*(input_ids != 102).long()
...
factor = ... # 计算权重w,后面会讲
...
# 得到韵母、声母和声调的输出
prediction_scores, sm_scores,ym_scores,sd_scores = self.cls(encoded_x)
...
loss_fct = self.loss_fct
if labels is not None and pinyin_labels is not None:
active_loss = loss_mask.view(-1) == 1
...
# 将不需要计算loss的部分的label更新成-100(因为CrossEntropy默认忽略-100这个index)
# 然后使用CrossEntropyLoss计算loss
# 计算声母loss
active_labels = torch.where(
active_loss, pinyin_labels[...,0].view(-1), torch.tensor(loss_fct.ignore_index).type_as(pinyin_labels)
)
sm_loss = loss_fct(sm_scores.view(-1, self.cls.Phonetic_relationship.pinyin.sm_size), active_labels)
# 计算韵母Loss
active_labels = torch.where(
active_loss, pinyin_labels[...,1].view(-1), torch.tensor(loss_fct.ignore_index).type_as(pinyin_labels)
)
ym_loss = loss_fct(ym_scores.view(-1, self.cls.Phonetic_relationship.pinyin.ym_size), active_labels)
# 计算声调loss
active_labels = torch.where(
active_loss, pinyin_labels[...,2].view(-1), torch.tensor(loss_fct.ignore_index).type_as(pinyin_labels)
)
sd_loss = loss_fct(sd_scores.view(-1, self.cls.Phonetic_relationship.pinyin.sd_size), active_labels)
# 最后将这三个loss相加,得到L^p
phonetic_loss=(sm_loss+ym_loss+sd_loss)/3
def weighted_mean(weight, input):
return torch.sum(weight * input) / torch.sum(weight)
# w和L^p相乘,求得加权后的损失
phonetic_loss = weighted_mean(factor.view(-1), phonetic_loss)
# end if
...
...
```
Similarity
在计算拼音预测的Loss时,要乘以一个权重,以便于降低错字对拼音预测的干扰。Similary模块就是用于这个权重的计算。
根据源码分析,作者目的是降低错字的Loss权重。根据论文中的描述,这个还挺重要的
源码如下:
```python
class Dynamic_GlyceBertForMultiTask(BertPreTrainedModel):
def __init__(self, config):
super(Dynamic_GlyceBertForMultiTask, self).__init__(config)
self.bert = GlyceBertModel(config) # Encoder
self.cls = MultiTaskHeads(config) # Projection和Decoder
self.loss_fct = CrossEntropyLoss(reduction='none')
...
def forward(...):
...
outputs_x = self.bert(...) # 错误句子的BERT输出
encoded_x = outputs_x[0]
if tgt_pinyin_ids is not None:
# 开始对正确的句子进行编码。这里不需要更新梯度,所以用torch.no_grad封装一下
with torch.no_grad():
outputs_y = self.bert(...) # 正确句子的bert输出
encoded_y = outputs_y[0]
# self.cls.Phonetic_relationship.transform 就是 Pron Projection
pron_x = self.cls.Phonetic_relationship.transform(encoded_x)
pron_y = self.cls.Phonetic_relationship.transform(encoded_y)
# 求正确句子和错误句子对应token的相似度
sim_xy = F.cosine_similarity(pron_x, pron_y, dim= -1)
# 根据相似度求权重。这个factor就是图中的w。var是超参,作者取的应该是1
factor = torch.exp( -((sim_xy -1.0) / var).pow(2)).detach()
```
根据源码分析,我们可以得出以下结论:
- 相似度函数使用的是余弦相似度。(余弦相似度的范围是[-1,1],其结果越大表示越相似,1表示完全一致)。
- 权重计算公式为:$$\begin{aligned}w=e^{-(s-1)^2}\end{aligned}$$
- 对于正确的字,由于使用的是同一个BERT和Pron Projection,所以它们向量的几乎接近1。(这里之所以不是1,是因为正确字的特征向量是结合了上下文的,因为上下文不一样,所以它们的特征向量也不会完全相同)。
- 对于错误的字,因为字不同,所以embedding肯定也不一样,所以相似度小于1,最终权重也小于1。但按照公式来看,即使相似度为-1的情况下,权重也有 $e^{-4}$,约为0.018。
- 综上,作者是想让错字的拼音预测Loss小一点。
模型训练
预训练
作者在正式训练前,使用wiki2019zh数据集预训练了SCOPE模型。该数据集包含100w个文章,作者将其分解成句子,然后使用混淆集(confusion set)构造数据集。
构造方式为:随机替换15%的字。对于被替换的字,80%使用混淆字替换,10%进行随机替换,10%不替换。
作者预训练好的模型如下:FPT(Further Pre-training)
数据集
训练数据:Wang271K+SIGHAN13训练集+SIGHAN14训练集+SIGHAN15训练集
作者并没有和其他论文一样,先使用Wang271K训练,再使用SIGHAN微调,而是直接把它们混合起来一起训练。
测试集: SIGHAN15,14,13
模型预测
Constrained Iterative Correction(约束迭代矫正)
作者提出“模型通常会矫枉过正(overcorrect)”,所以他发明了一个简单有效的方法来解决这个问题,同时这个方法也解决了连续错字的情况。
作者的思路是这样的,首先使用多次预测的方式可以解决连续的错字。例如对于这句话:“我什么都不集的了”。
若你将其送给模型,他通常会给你这样的结果:“我什么都不记的了”。即,现有的CSC模型通常都只能处理单个字的错误,很难处理连续错字。
若你将预测结果“我什么都不记的了”送给模型进行预测,模型的第二次的输出大概率就会输出“我什么都不记得了”
到这里,感觉好像挺好的,只要进行两次,或者更多反复的预测,直到这句话不再发生改变,这样不就可以处理更长的连续错字啦?没错,实事确实是这样。
然而,会出现另一种情况,就是在修改连续错字时,其他位置的错字发生了改变。
例如:“他喜欢唱跳rap烂酋”。我们现在将其连续重复预测,可能会得到如下的结果:
- 她喜欢唱跳rap篮酋
- 她喜欢唱跳rap篮球
- 他喜欢唱跳rap篮球
前两次预测符合预期,但却在第三次发生了意外,将“她”过度矫正为了“他”(可能是因为模型看到了篮球,就认为应该是男他)。这应该就是作者说的“过度矫正(overcorrect)”。
为了解决过度矫正的问题,作者进行了“加窗”处理,即在重复预测时,只允许对上次修改错字的周边字进行修改。例如:假设窗口大小为1,第一次预测对“烂”字进行修改,那么在第二次预测时,只能对“烂”字左边和右边的1个字进行修改,如果对更远地方的字进行修改时,则不采纳。
经过“加窗”处理后,“他喜欢唱跳rap烂酋” 这句话的预测流程变为了这样(假设窗口大小为1):
- 她喜欢唱跳rap篮酋。 对“烂”字进了修改,则对其进行加窗
- 她喜欢唱跳ra[p篮球]。本次对“酋”字进行了修改,在窗口范围内,采纳修改。
- 他喜欢唱跳rap[篮球。] 本次对“他”字进行了修改,其不在窗口范围内,所以不予采纳。将句子恢复成“她喜欢唱跳rap篮球”
最终,预测过程通过“连续预测+加窗”预测出了正确的结果。
该算法包含两个超参数:
- 窗口的大小,作者采用的是1
- 重复预测的次数,作者采用的是1,即重复预测1次。
源码分析:
```python
def predict_step(self, batch, batch_idx, dataloader_idx=0):
# 注意,这里一个batch是一条句子。即一次预测一句
input_ids, pinyin_ids, labels, pinyin_labels, ids, srcs, tokens_size = batch
mask = (input_ids != 0) * (input_ids != 101) * (input_ids != 102).long()
batch_size, length = input_ids.shape
pinyin_ids = pinyin_ids.view(batch_size, length, 8)
# 第一遍:进行前向传递,然后argmax求出每个token的index
logits = self.forward(input_ids=input_ids, pinyin_ids=pinyin_ids).logits
predict_scores = F.softmax(logits, dim=-1)
predict_labels = torch.argmax(predict_scores, dim=-1) * mask
# 如果测试集是sighan13,则不对“地”和“得”这两个字进行预测
if '13' in self.args.label_file:
predict_labels[(predict_labels == self.tokenizer.token_to_id('地')) | (predict_labels == self.tokenizer.token_to_id('得'))] = \
input_ids[(predict_labels == self.tokenizer.token_to_id('地')) | (predict_labels == self.tokenizer.token_to_id('得'))]
# 保存一下第一次预测的结果
pre_predict_labels = predict_labels
# 进行第二次预测(可以重复多次)
for _ in range(1):
record_index = [] # 记录上次预测结果中对哪个token进行了修改
# 遍历input和pred,找出修改了的token对应的index
for i,(a,b) in enumerate(zip(list(input_ids[0,1:-1]),list(predict_labels[0,1:-1]))):
if a!=b:
record_index.append(i)
# 用第一次的预测结果作为输入,然后再预测一次
input_ids[0,1:-1] = predict_labels[0,1:-1]
sent, new_pinyin_ids = decode_sentence_and_get_pinyinids(input_ids[0,1:-1].cpu().numpy().tolist())
if new_pinyin_ids.shape[1] == input_ids.shape[1]:
pinyin_ids = new_pinyin_ids
pinyin_ids = pinyin_ids.to(input_ids.device)
# print(input_ids.device, pinyin_ids.device)
logits = self.forward(input_ids=input_ids, pinyin_ids=pinyin_ids).logits
predict_scores = F.softmax(logits, dim=-1)
# 得到第二次的预测结果
predict_labels = torch.argmax(predict_scores, dim=-1) * mask
# 遍历本次的预测结果的每个token
for i,(a,b) in enumerate(zip(list(input_ids[0,1:-1]),list(predict_labels[0,1:-1]))):
# 若这个token被修改了,且在窗口范围内,则什么都不做。
if a!=b and any([abs(i-x)<=1 for x in record_index]):
print(ids,srcs)
print(i+1,)
else:
# 若 a==b ,则执行 predict_labels[0,i+1] = input_ids[0,i+1] 和不执行是一样的
# 若 a==b and any(...) == False: 那么表示该token进行了修改,但不在窗口范围内,则恢复到原本的样子
predict_labels[0,i+1] = input_ids[0,i+1]
# TODO,没看懂这个break是想干嘛
if predict_labels[0,i+1] == input_ids[0,i+1]:
break
# 如果测试集是sighan13,则不对“地”和“得”这两个字进行预测
if '13' in self.args.label_file:
predict_labels[(predict_labels == self.tokenizer.token_to_id('地')) | (predict_labels == self.tokenizer.token_to_id('得'))] = \
input_ids[(predict_labels == self.tokenizer.token_to_id('地')) | (predict_labels == self.tokenizer.token_to_id('得'))]
# 返回预测结果
return {
"tgt_idx": labels.cpu(),
"post_pred_idx": predict_labels.cpu(),
"pred_idx": pre_predict_labels.cpu(),
"id": ids,
"src": srcs,
"tokens_size": tokens_size,
}
```
模型结果
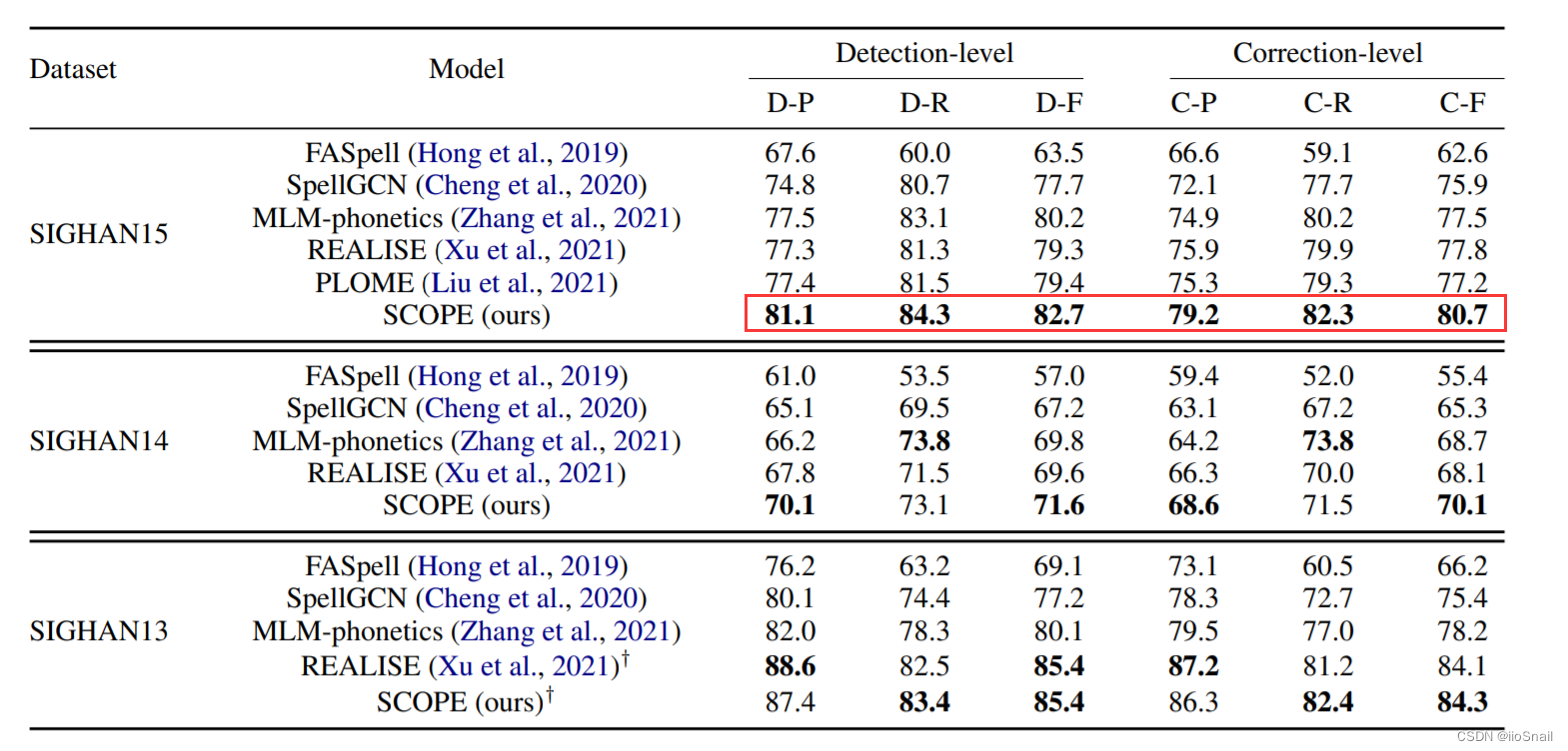
截止“2023-04”,这应该是学术圈表现最好的CSC工作了。
消融实验
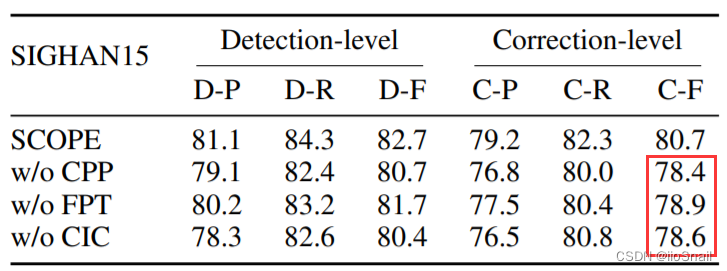
- w/o CPP:without CPP。不使用拼音预测辅助任务。
- w/o FPT:不使用预训练模型。
- w/o CIC:不使用约束矫正方法。
论文复现
使用作者提供的代码,未进行任何修改,环境配置也保持一致,最终复现结果如下:
1.跑了30个epoch,最后的5个epoch的checkpoint如下:
```
# 格式为 epoch={epoch}-df={detection sentence f1}-cf={correct sentence f1}.ckpt
# 这里的f1都不包含最后的CIC模块,即网络直接预测出的结果
epoch=23-df=79.3537-cf=78.0969.ckpt
epoch=25-df=80.1070-cf=78.1445.ckpt
epoch=26-df=80.1810-cf=78.5520.ckpt
epoch=28-df=80.1802-cf=78.7387.ckpt
epoch=29-df=80.2158-cf=78.5971.ckpt
```
单看epoch=29-df=80.2158-cf=78.5971.ckpt可以看出与作者消融实验中的w/o CIC结果一致。
2.使用最后一个epoch的checkpinyin进行sighan2015的测试结果如下:
``` # epoch 29 # without CIC 'sent-detect-acc': 85.36363636363636, 'p': 78.10858143607706, 'r': 82.43992606284658, 'f1': 80.21582733812951 'sent-correct-acc': 84.54545454545455, 'p': 76.5323992994746, 'r': 80.77634011090574, '': 78.59712230215827 'char-detect-f1': 86.45614035087719, 'f1': 91.12964366944655 # with CIC 'sent-detect-acc': 86.27272727272727, 'p': 79.75133214920072, 'r': 82.99445471349352, 'f1': 81.34057971014492, 'sent-correct-acc': 85.45454545454545, 'p': 78.15275310834814, 'r': 81.33086876155268, 'f1': 79.71014492753623, 'char-detect-f1': 87.1578947368421, 'f1': 91.38972809667673 ```
在SIGHAN2015上的w/o CIC部分的correct指标完全符合论文结果,但detect部分不符。但with CIC部分的结果与论文的结果比差了整整一个点
3.使用最后一个epoch的checkpinyin进行sighan2014的测试结果如下:
``` # epoch 29 # without CIC 'sent-detect-acc': 77.30696798493409, 'p': 65.70397111913357, 'r': 70.0, 'f1': 67.78398510242086 'sent-correct-acc': 76.45951035781545, 'p': 64.07942238267148, 'r': 68.26923076923077, 'f1': 66.10800744878958 'char-detect-f1': 79.7157622739018, 'f1': 86.74351585014409} # with CIC 'sent-detect-acc': 78.53107344632768, 'p': 67.99276672694394, 'r': 72.3076923076923, 'f1': 70.0838769804287, 'sent-correct-acc': 77.68361581920904, 'p': 66.36528028933093, 'r': 70.57692307692308, 'f1': 68.4063373718546, 'char-detect-f1': 80.81580624601658, 'f1': 87.68683274021353 ```
在SIGHAN14上同样无法复现论文结果,甚至去除CIC后,效果还不如ReaLiSe
4.使用最后一个epoch的checkpinyin进行sighan2013的测试结果如下:
``` epoch29 # without CIC 'sent-detect-acc': 81.2, 'p': 86.12021857923497, 'r': 81.15345005149331, 'f1': 83.56309650053022 'sent-correct-acc': 80.30000000000001, 'p': 85.13661202185793, 'r': 80.22657054582905, 'f1': 82.6086956521739 'char-detect-f1': 90.96091205211727, 'f1': 94.31866723622383 # with CIC 'sent-detect-acc': 80.4, 'p': 85.33916849015317, 'r': 80.32955715756952, 'f1': 82.75862068965517, 'sent-correct-acc': 79.7, 'p': 84.57330415754923, 'r': 79.6086508753862, 'f1': 82.0159151193634 'char-detect-f1': 90.6655844155844, 'f1': 94.14780008543357 ```
Sighan2013上也跑不过ReaLise,而且加了CIC后,反而下降了
关于无法完全复现论文结论的问题,我在github(#7)上问了,作者表示在构造数据集时因为有shuffle操作,而这个shuffle没指定seed,所以训练时的数据顺序和原论文是不一样的。
个人总结
作者提出的方法主要有以下借鉴之处:
- 作者提出了CPP辅助任务,可以让Encoder模型学会对汉语拼音进行编码。
- 作者提供了一个 预训练好的SCOPE模型,后续的CSC任务可以用这个做迁移学习
- 作者提出了CIC(约束矫正方法),可以用在预测阶段。


