A Native RAG Example with LangChain

Source Code: Github
Table of Content
1. Overview
As is well known, LLMs can only anwser what they know. If a user asks about somethings that an LLM doesn't know, it may respond incorrectly — a phenomenon known as hallucination.
To address this issue, users can provide references to the LLM.
Example (Without reference):
``` User: Do you know what's the homework today? LLM: Sorry, I don't know. ```
To enable the LLM to anwser the question accurately, we can provide references to the LLM and modify the prompt as follows:
``` User: Do you know what's the homework today? Truly Prompt: Please answer the following question: """ Do you know what's the homework today? """ You can refer to the following knowledge: """ The homework is to complete exercises 5.1 to 5.3 on page 87. ... """ LLM: Yes, your homework is to complete exercises 5.1 to 5.3 on page 87. ```
While this may seem simple in the example, the real chanllenge is how to query the relevant knowledge, which is the core purpose of RAG (Retrieval-augmented Generation).
2. Native RAG Overview
RAG is a complex framework composed of multiple modules. Each module is designed to improve the accuracy of LLM's output.
If only the basic RAG modules are used, it is refered to as native RAG.
The native RAG process can be illustrated with the following diagram:
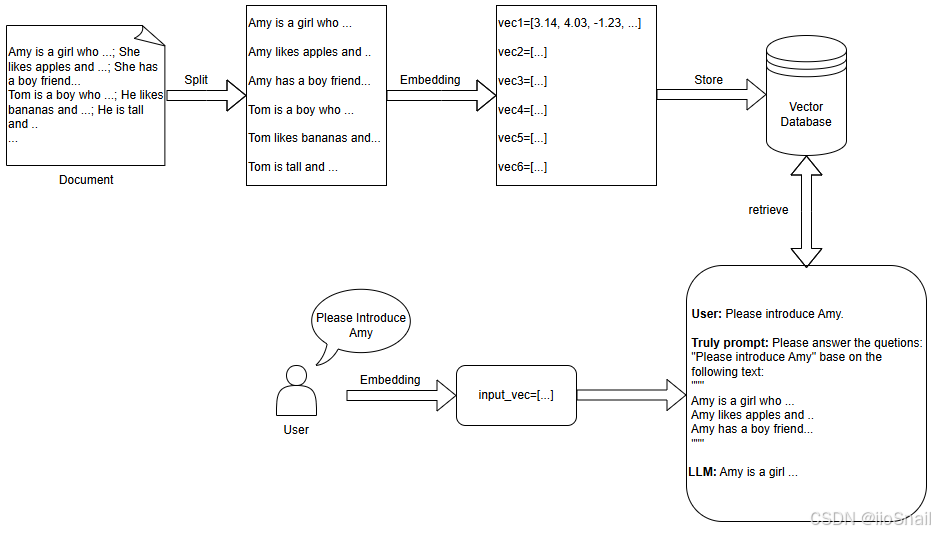
The native RAG pipeline consists of several basic modules, as depicted in the diagram above:
- Document Splitting: Users can upload a document containing long-form text. So, the first step is to split the document into small chunks.
- Text Embedding: To compute the similarity sentences between user queries and doucment content, text must be converted into vector representations. The commonly used methods include:
- Using embedding APIs (e.g., OpenAI's API)
- Using deep learning-based embedding models (e.g., BERT)
- Using frequency-based methods (e.g., TF-IDF)
- Vector Storage: After generating embeddings, these vectors need to be stored in a vector database. Vector database is designed for efficient vector storage and retrieval. You can query similar vectors conveniently by its API. Common vector databases include Faiss and Chroma.
- Knowledge Retrieval: When a user queries the LLM, relevant knowledge is retrieved from the vector database. The first step is to embed the user's query and then to retreive the $k$ most similar knowledge entries from vector database.
- Prompt Construction: After retreiving knowledges, it needs to build prompt before chating with LLM. For example, the prompt can be "Please answer the question #{question} based on the following knowledge #{knowledge}". These placeholoders need to be replaced with actual data.
3. Practice: Implementing Native RAG with LangChain
Overview
In this chapter, we will implement a basic native RAG system using LangChain.
LangChain is a Python framework for building LLM-powered applications. Don't worry if you are unfamiliar with it - the framework is just a collection of many tools. You can learn it during using it.
For simplicity, our document contains descriptive profiles of multiple individuals.
Environment Setup
Install dependencies.
``` !pip install -U langchain langchain-community langchain-core langchain-deepseek !pip install faiss-cpu ```
Download mock document from google drive.
```python # If you are using Google colab, you can use the command to download it. !gdown 1n8HhgQenifEBGJKMcOwh53q5JOJbv58a ```
The document looks like as follows:
``` Alex is a dedicated software engineer ... Jordan is an enthusiastic ... ... ```
Split Document
Load document by TextLoader
```python
from langchain.document_loaders import TextLoader
loader = TextLoader("description.txt")
document = loader.load()
print(document)
```
```
[Document(metadata={'source': 'description.txt'}, page_content="Alex is a dedicated ....)]
```
Split document sentence by sentence.
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Splitter to split document into chunks.
splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ". ", "! ", "? ", "\u200b"], # Split by these sperators.
chunk_size=1, # Every chunk has at least one token.
chunk_overlap=0, # No overlap between chunks.
keep_separator=False # discard sperators after splitting.
)
docs = splitter.split_documents(document)
print(docs)
```
``` [ Document(page_content='Alex is a ... problems'), Document(page_content='Alex has ... Python'), Document(page_content='Alex thrives ... developers'), ... ] ```
Define Embedding Model
Here, we use embedding model on HuggingFace to embed our document.
```python
from langchain.embeddings import HuggingFaceEmbeddings
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
# Try to embed a sentence into a vector.
emb = embedding_model.embed_query("Hello, I'm learning LLM.")
print(type(emb)) # list.
print(len(emb)) # 768
```
Build Vector Database
After preparing our documents and embedding model, we can use Langchain to build our vector database conveniently. Here, we use Faiss as our vector database.
```python from langchain.vectorstores import FAISS vectorstore = FAISS.from_documents(docs, embedding_model) ```
We can query the $k$ most similar documents by similarity_search function easily.
```python
vectorstore.similarity_search("Introduce Alex", k=3)
```
``` [ Document(page_content='Alex is a ... problems'), Document(page_content='Alex thrives ... developers'), Document(page_content='Alex has ... and Python') ] ```
Chat with LLM
Now, we can proceed to interact with LLM. For simplicity, we don't employ LLM by ourself. Instead, we use online LLM api such as OpenAI and Deepseek.
Here, we use Deepseek as exmaple. First, you should top up a little money and get your API by this link.
```python
import os
from langchain_deepseek import ChatDeepSeek
# Config your deekseek
os.environ["DEEPSEEK_API_KEY"] = "" # TODO
llm = ChatDeepSeek(
model="deepseek-chat"
)
```
Let's try to ask something.
```python
messages = [
("human", "Hi, do you know Alex?"),
]
ai_msg = llm.invoke(messages)
print(ai_msg.content)
```
``` It depends! If you're referring to a specific person named Alex, I don’t have personal knowledge of individuals ... ```
Next, let's build our prompt.
```python
prompt_template = """You are an AI assistant. Please answer user's question based on the following content:
'''
{content}
'''
Answer user's question directly. Don't need to say "Based on the information".
"""
```
Finally, let's combine all processes into a function.
```python
def chat(question: str):
docs = vectorstore.similarity_search(question, k=3)
content = '\n'.join([doc.page_content for doc in docs])
messages = [
("system", prompt_template.format(content=content)),
("human", question),
]
resp = llm.invoke(messages)
return resp.content
```
Let's try some instances.
```python
print(chat("Who is software engineer?"))
print(chat("Who can analyse data?"))
```
``` Alex is a software engineer with over five years ... Both Casey and Sage can analyze data. Casey has strong analytica ... ```
Reference
- LangChain Tutorials : https://python.langchain.com/docs/tutorials/


