PyTorch Beginner's Tutorial (5) - Machine Translation Using nn.Transformer (English to Chinese)

Overview
In this post, we will implement an English-to-Chinese machine translation task using Pytorch's nn.Transformer.
This post assumes you have a basic understanding of Transformers, especially regarding the model’s input/output, training methods, inference procedures, and the Mask component. These topics are covered in the knowledge points of the previous article.
You can find the source code for this post in the Github Project.
Final Result of This Post:
```python
translate("Alright, this project is finished. Let's see how good this is")
```
``` '好吧,这个项目完成了。让我们看看这是多好的。' ```
This is the result after training for 10 hours. (Note that one epoch wasn’t completed, and the loss could still decrease further.)
Environment Setup
The following environment is primarily used in this tutorial:
``` torch>=1.11.0 tokenizers==0.12.1 torchtext==0.12.0 tensorboard==2.8.0 ```
First, let’s import the necessary packages for this tutorial:
```python import os import math import torch import torch.nn as nn # Hugging Face tokenizer, GitHub repo: https://github.com/huggingface/tokenizers from tokenizers import Tokenizer # For building the vocabulary from torchtext.vocab import build_vocab_from_iterator from torch.utils.data import Dataset from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torch.nn.functional import pad, log_softmax from pathlib import Path from tqdm import tqdm ```
The dataset consists of two files: train.en and train.zh. Both are text files containing English and Chinese sentences.
This article uses the AI Challenger Translation 2017 dataset. I’ve made some simple adjustments and only used the train.en and train.zh files (for simplicity, the validation set is not used in this article). Additionally, I’ve included the initialized cache files, which you can directly extract.
If you don’t want to use my cached files, you can delete the *.pt files or set use_cache=False.
Define some global configurations, such as the working directory, batch size during training, epochs, etc.
```python
# Working directory where the cache files and model checkpoints will be stored
work_dir = Path("./dataset")
# Directory for storing the trained models
model_dir = Path("./drive/MyDrive/model/transformer_checkpoints")
# The last checkpoint of the model. If it's the first run, set to None. If paused, specify the latest model for resumption.
model_checkpoint = None # 'model_10000.pt'
# Create the working directory if it does not exist
if not os.path.exists(work_dir):
os.makedirs(work_dir)
# Create the model directory if it does not exist
if not os.path.exists(model_dir):
os.makedirs(model_dir)
# File path for English sentences
en_filepath = './dataset/train.en'
# File path for Chinese sentences
zh_filepath = './dataset/train.zh'
# Define a method to get the number of lines in a file.
def get_row_count(filepath):
count = 0
for _ in open(filepath, encoding='utf-8'):
count += 1
return count
# Number of English sentences
en_row_count = get_row_count(en_filepath)
# Number of Chinese sentences
zh_row_count = get_row_count(zh_filepath)
assert en_row_count == zh_row_count, "The number of lines in the English and Chinese files are inconsistent!"
# Total sentence count, mainly used for progress display
row_count = en_row_count
# Define the maximum sentence length. Sentences shorter than this will be padded, and those longer will be truncated.
max_length = 72
print("Total number of sentences:", en_row_count)
print("Maximum sentence length:", max_length)
# Define English and Chinese vocabularies, both will be initialized later as Vocab class objects
en_vocab = None
zh_vocab = None
# Define batch size. Since it's training text and requires less memory, it can be set larger.
batch_size = 64
# Number of epochs. It doesn't need to be too large as there are many sentences.
epochs = 10
# Save the model every 'save_after_step' steps to prevent loss in case of program crashes.
save_after_step = 5000
# Whether to use caching. Due to the large size of the files, initialization is slow, so the initialized files will be persisted.
use_cache = True
# Define the training device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("batch_size:", batch_size)
print("Save model every {} steps".format(save_after_step))
print("Device:", device)
```
``` Total number of sentences: 10000000 Maximum sentence length: 72 batch_size: 64 Save model every 5000 steps Device: cuda ```
Data Preprocessing
This chapter focuses on data processing, with the main steps being:
- Constructing English and Chinese dictionaries. The English dictionary uses a subword approach, while the Chinese dictionary performs word segmentation based on characters.
- Constructing the Dataset and DataLoader, where the text is converted into numerical indices and padding is applied.
Text Tokenization and Dictionary Construction
For English tokenization, this article uses a subword method。The tokenizer used is the BERT model from Hugging Face, which is simple to use and doesn’t require additional learning—just reading this article will be enough to understand it.
Next, let's construct the English dictionary:
```python
# Load the base tokenizer model, using the standard BERT model. "uncased" means it is case-insensitive.
tokenizer = Tokenizer.from_pretrained("bert-base-uncased")
def en_tokenizer(line):
"""
Define the English tokenizer, which will also be used later.
:param line: An English sentence, for example, "I'm learning Deep learning."
:return: The result after subword tokenization, for example: ['i', "'", 'm', 'learning', 'deep', 'learning', '.']
"""
# Use BERT for tokenization and obtain tokens. `add_special_tokens` means that special characters like `<bos>` and `<eos>` won't be added to the result.
return tokenizer.encode(line, add_special_tokens=False).tokens
```
If you're using a newer version and the previous code throws an error, you can modify it as follows:
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def en_tokenizer(line):
return tokenizer.convert_ids_to_tokens(tokenizer.encode(line, add_special_tokens=False))
```
Let's test the English tokenizer:
```python
print(en_tokenizer("I'm a English tokenizer."))
```
``` ['i', "'", 'm', 'a', 'english', 'token', '##izer', '.'] ```
In the tokenization result above, the word "tokenizer" is split into two subwords:
tokenand##izer. The##indicates that this part of the word is connected to the preceding part.
Next, let's start building the vocabulary. We will first define a yield function to produce an iterable tokenization result:
```python
def yield_en_tokens():
"""
This function yields one tokenized English sentence at a time. The reason for using yield is to save memory.
If we tokenize everything first and then build the vocabulary, a large amount of text will be stored in memory,
causing a memory overflow.
"""
file = open(en_filepath, encoding='utf-8')
print("-------Starting to build the English vocabulary-----------")
for line in tqdm(file, desc="Building English vocabulary", total=row_count):
yield en_tokenizer(line)
file.close()
```
```python
# Specify the path for the English vocabulary cache file
en_vocab_file = work_dir / "vocab_en.pt"
# If using a cache and the cache file exists, load the cache
if use_cache and os.path.exists(en_vocab_file):
en_vocab = torch.load(en_vocab_file, map_location="cpu")
# Otherwise, construct the vocabulary from scratch
else:
# Build the vocabulary
en_vocab = build_vocab_from_iterator(
# Provide an iterable list of tokens, e.g. [['i', 'am', ...], ['machine', 'learning', ...], ...]
yield_en_tokens(),
# Set the minimum frequency to 2, meaning a word must appear at least twice to be included
min_freq=2,
# Add these special tokens at the beginning of the vocabulary
specials=["<s>", "</s>", "<pad>", "<unk>"],
)
# Set the default index for the vocabulary. If a token is not found during index conversion, this index will be used
en_vocab.set_default_index(en_vocab["<unk>"])
# Save the cache file
if use_cache:
torch.save(en_vocab, en_vocab_file)
```
```python
# Print to check the result
print("English vocabulary size:", len(en_vocab))
print(dict((i, en_vocab.lookup_token(i)) for i in range(10)))
```
```
English vocabulary size: 27584
{0: '<s>', 1: '</s>', 2: '<pad>', 3: '<unk>', 4: '.', 5: ',', 6: 'the', 7: "'", 8: 'i', 9: 'you'}
```
Next, let's build the Chinese vocabulary. Since there are many words in Chinese, out-of-vocabulary (OOV) issues can easily arise. A simple approach is to treat each character as a token without segmentation. This is reasonable for Chinese because splitting a word into individual characters usually still retains its meaning. For example, the word "单词" (word) can be split into "单" (single) and "词" (word) and still convey the original meaning.
Building the Chinese vocabulary is similar to the process for English:
```python
def zh_tokenizer(line):
"""
Define a Chinese tokenizer.
:param line: A Chinese sentence, e.g., '机器学习' (machine learning)
:return: Tokenized result, e.g., ['机', '器', '学', '习']
"""
return list(line.strip().replace(" ", ""))
def yield_zh_tokens():
file = open(zh_filepath, encoding='utf-8')
for line in tqdm(file, desc="Building Chinese dictionary", total=row_count):
yield zh_tokenizer(line)
file.close()
```
```python
zh_vocab_file = work_dir / "vocab_zh.pt"
if use_cache and os.path.exists(zh_vocab_file):
zh_vocab = torch.load(zh_vocab_file, map_location="cpu")
else:
zh_vocab = build_vocab_from_iterator(
yield_zh_tokens(),
min_freq=1,
specials=["<s>", "</s>", "<pad>", "<unk>"],
)
zh_vocab.set_default_index(zh_vocab["<unk>"])
torch.save(zh_vocab, zh_vocab_file)
```
```python
# Print and check the results
print("Chinese vocabulary size:", len(zh_vocab))
print(dict((i, zh_vocab.lookup_token(i)) for i in range(10)))
```
```
Chinese vocabulary size: 8280
{0: '<s>', 1: '</s>', 2: '<pad>', 3: '<unk>', 4: '。', 5: '的', 6: ',', 7: '我', 8: '你', 9: '是'}
```
Dataset and Dataloader
A dictionary can be used to define the Dataset. The dataset returns a pair of sentences each time, for example: ([6, 8, 93, 12, ..], [62, 891, ...]), where the first list is the English sentence and the second list is the Chinese sentence.
```python
class TranslationDataset(Dataset):
def __init__(self):
# Load English tokens
self.en_tokens = self.load_tokens(en_filepath, en_tokenizer, en_vocab, "Building English tokens", 'en')
# Load Chinese tokens
self.zh_tokens = self.load_tokens(zh_filepath, zh_tokenizer, zh_vocab, "Building Chinese tokens", 'zh')
def __getitem__(self, index):
return self.en_tokens[index], self.zh_tokens[index]
def __len__(self):
return row_count
def load_tokens(self, file, tokenizer, vocab, desc, lang):
"""
Load tokens, which means converting text sentences into indices.
:param file: File path, e.g., "./dataset/train.en"
:param tokenizer: Tokenizer, e.g., en_tokenizer function
:param vocab: Vocabulary, a Vocab class object, e.g., en_vocab
:param desc: Description for progress display, e.g., 'Building English tokens'
:param lang: Language. Used for distinguishing when creating cache files. For example, 'en'
:return: Returns the constructed tokens, e.g., [[6, 8, 93, 12, ..], [62, 891, ...], ...]
"""
# Define the cache file path
cache_file = work_dir / "tokens_list.{}.pt".format(lang)
# If caching is enabled and the cache file exists, load directly
if use_cache and os.path.exists(cache_file):
print(f"Loading cache file {cache_file}, please wait...")
return torch.load(cache_file, map_location="cpu")
# Initialize the list to store the results
tokens_list = []
# Open the file
with open(file, encoding='utf-8') as file:
# Read line by line
for line in tqdm(file, desc=desc, total=row_count):
# Tokenize the line
tokens = tokenizer(line)
# Convert the tokenized result into indices using the vocabulary
tokens = vocab(tokens)
# Append the result to the list
tokens_list.append(tokens)
# Save the cache file
if use_cache:
torch.save(tokens_list, cache_file)
return tokens_list
```
```python dataset = TranslationDataset() ```
After defining the dataset, let's take a quick look:
```python print(dataset.__getitem__(0)) ```
``` ([11, 2730, 12, 554, 19, 17210, 18077, 27, 3078, 203, 57, 102, 18832, 3653], [12, 40, 1173, 1084, 3169, 164, 693, 397, 84, 100, 14, 5, 1218, 2397, 535, 67]) ```
The dataset does not include
<bos>and<eos>tokens. This action and padding are handled within the dataloader.
Next, let's define the Dataloader.
Before defining the Dataloader, we first need to define the collate_fn, because the fields returned by our dataset cannot be easily combined into batches and require further processing. These operations are all handled within the collate_fn.
```python
def collate_fn(batch):
"""
Further process the data from the dataset and assemble a batch.
:param batch: A batch of data, for example:
[([6, 8, 93, 12, ..], [62, 891, ...]),
....
...]
:return: The padded and length-matched data, including src, tgt, tgt_y, n_tokens
where src is the original sentence, which is the sentence to be translated
tgt is the target sentence: the translated sentence, excluding the last token
tgt_y is the label: the translated sentence, excluding the first token, i.e., <bos>
n_tokens: The number of tokens in tgt_y, excluding <pad>.
"""
# Define the index for '<bos>', which is 0 in the vocabulary, so here it is also 0
bs_id = torch.tensor([0])
# Define the index for '<eos>'
eos_id = torch.tensor([1])
# Define the index for <pad>
pad_id = 2
# Lists to store the processed src and tgt
src_list, tgt_list = [], []
# Iterate through each sentence pair
for (_src, _tgt) in batch:
"""
_src: The source sentence, e.g., the index corresponding to 'I love you'
_tgt: The target sentence, e.g., the index corresponding to '我 爱 你'
"""
processed_src = torch.cat(
# Concatenate <bos>, sentence index, and <eos>
[
bs_id,
torch.tensor(
_src,
dtype=torch.int64,
),
eos_id,
],
0,
)
processed_tgt = torch.cat(
[
bs_id,
torch.tensor(
_tgt,
dtype=torch.int64,
),
eos_id,
],
0,
)
"""
Pad sentences to the length of max_padding and add them to the list.
pad: If processed_src is [0, 1136, 2468, 1349, 1]
The second argument is: (0, 72-5)
The third argument is: 2
This means padding processed_src with 0 padding of 2 on the left and 67 padding of 2 on the right.
The final result will be: [0, 1136, 2468, 1349, 1, 2, 2, 2, ..., 2]
"""
src_list.append(
pad(
processed_src,
(0, max_length - len(processed_src),),
value=pad_id,
)
)
tgt_list.append(
pad(
processed_tgt,
(0, max_length - len(processed_tgt),),
value=pad_id,
)
)
# Stack multiple src sentences together
src = torch.stack(src_list)
tgt = torch.stack(tgt_list)
# tgt_y is the target sentence with the first token removed, i.e., without <bos>
tgt_y = tgt[:, 1:]
# tgt is the target sentence with the last token removed
tgt = tgt[:, :-1]
# Calculate the number of tokens to predict in this batch
n_tokens = (tgt_y != 2).sum()
# Return the batch result
return src, tgt, tgt_y, n_tokens
```
With the collate_fn function, we can now construct the dataloader.
```python train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn) ```
```python src, tgt, tgt_y, n_tokens = next(iter(train_loader)) src, tgt, tgt_y = src.to(device), tgt.to(device), tgt_y.to(device) ```
```python
print("src.size:", src.size())
print("tgt.size:", tgt.size())
print("tgt_y.size:", tgt_y.size())
print("n_tokens:", n_tokens)
```
``` src.size: torch.Size([64, 72]) tgt.size: torch.Size([64, 71]) tgt_y.size: torch.Size([64, 71]) n_tokens: tensor(1227) ```
Next, we can start building the translation model.
Model Construction
Since nn.Transformer does not include the Positional Encoding part, we need to implement it ourselves. Here, we’ll directly use an existing implementation.
```python
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Initialize the PE (positional encoding) tensor with shape (max_len, d_model)
pe = torch.zeros(max_len, d_model).to(device)
# Create a tensor [[0, 1, 2, 3, ...]]
position = torch.arange(0, max_len).unsqueeze(1)
# This is where the sin and cos functions are applied, with transformations using e and ln
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
# Compute PE(pos, 2i)
pe[:, 0::2] = torch.sin(position * div_term)
# Compute PE(pos, 2i+1)
pe[:, 1::2] = torch.cos(position * div_term)
# To facilitate computation, an extra batch dimension is added with unsqueeze
pe = pe.unsqueeze(0)
# If a parameter does not participate in gradient descent but should be saved when the model is saved,
# we use register_buffer
self.register_buffer("pe", pe)
def forward(self, x):
"""
x is the embedding of inputs, e.g., (1,7, 128), where batch size is 1, 7 words, each word has a dimension of 128
"""
# Add the positional encoding to the input.
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
```
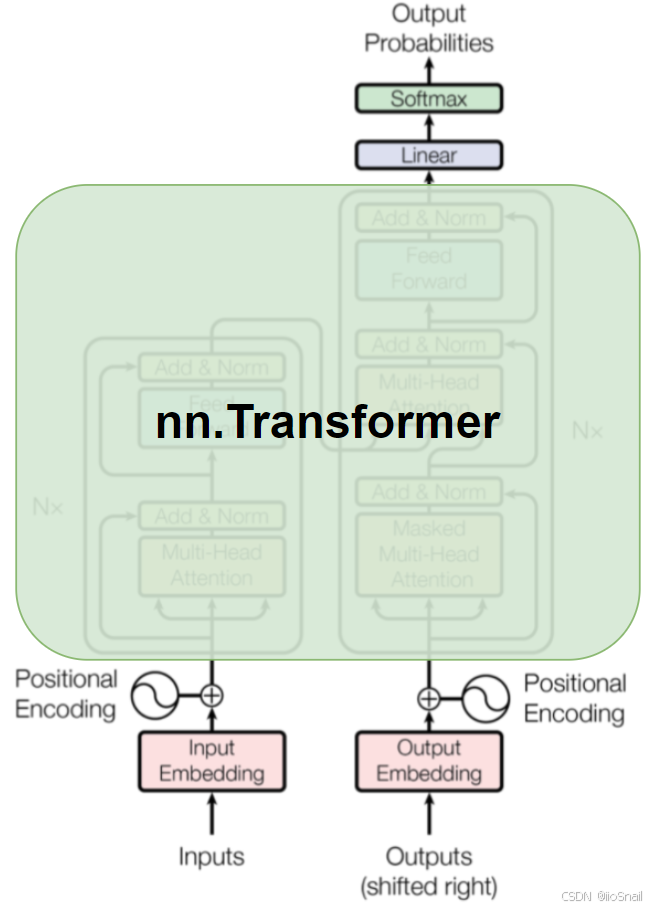
Next, let’s define a Transformer translation model. The nn.Transformer implementation only covers the green part of the Transformer shown in the diagram below, so we need to implement the rest ourselves:
```python
class TranslationModel(nn.Module):
def __init__(self, d_model, src_vocab, tgt_vocab, dropout=0.1):
super(TranslationModel, self).__init__()
# Define the embedding for the source sentence
self.src_embedding = nn.Embedding(len(src_vocab), d_model, padding_idx=2)
# Define the embedding for the target sentence
self.tgt_embedding = nn.Embedding(len(tgt_vocab), d_model, padding_idx=2)
# Define positional encoding
self.positional_encoding = PositionalEncoding(d_model, dropout, max_len=max_length)
# Define the Transformer
self.transformer = nn.Transformer(d_model, dropout=dropout, batch_first=True)
# Define the final prediction layer. Note that Softmax is not included here, as it's handled outside the model.
self.predictor = nn.Linear(d_model, len(tgt_vocab))
def forward(self, src, tgt):
"""
Perform the forward pass and output the Decoder's results. Note that self.predictor is not used here,
as training and inference behave differently, so it’s handled outside the model.
:param src: Source sentence batch, e.g., [[0, 12, 34, .., 1, 2, 2, ...], ...]
:param tgt: Target sentence batch, e.g., [[0, 74, 56, .., 1, 2, 2, ...], ...]
:return: Output of the Transformer, or the TransformerDecoder output.
"""
"""
Generate tgt_mask, a stepwise mask, e.g.:
[[0., -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf],
[0., 0., 0., -inf, -inf],
[0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0.]]
tgt.size()[-1] corresponds to the length of the target sentence.
"""
tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size()[-1]).to(device)
# Mask out the <pad> parts of the source sentence, e.g., [[False, False, False, ..., True, True, ...], ...]
src_key_padding_mask = TranslationModel.get_key_padding_mask(src)
# Mask out the <pad> parts of the target sentence
tgt_key_padding_mask = TranslationModel.get_key_padding_mask(tgt)
# Encode the source and target sentences
src = self.src_embedding(src)
tgt = self.tgt_embedding(tgt)
# Add positional information to the tokens of the source and target sentences
src = self.positional_encoding(src)
tgt = self.positional_encoding(tgt)
# Pass the prepared data through the transformer
out = self.transformer(src, tgt,
tgt_mask=tgt_mask,
src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask)
"""
Directly return the result from the transformer. Since the behaviors differ during training and inference,
the linear prediction layer is handled outside this model.
"""
return out
@staticmethod
def get_key_padding_mask(tokens):
"""
Generate key_padding_mask
"""
return tokens == 2
```
In nn.Transformer,
-infin the mask indicates masking, while0means no masking. For thekey_padding_mask,Trueindicates masking, andFalsemeans no masking.
```python
if model_checkpoint:
model = torch.load(model_dir / model_checkpoint)
else:
model = TranslationModel(256, en_vocab, zh_vocab)
model = model.to(device)
```
Try calling the model to verify if it runs properly.
```python model(src, tgt).size() ```
``` torch.Size([64, 71, 256]) ```
```python model(src, tgt) ```
```
tensor([[[ 0.3853, -0.8223, 0.5280, ..., -2.4575, 2.5116, -0.5928],
[ 1.5033, -0.3207, 0.5466, ..., -2.5268, 2.2986, -1.6524],
[ 0.7981, 0.4327, 0.5015, ..., -2.1362, 0.7818, -1.1500],
...,
[ 0.6166, -0.8814, -0.0232, ..., -1.6519, 2.8955, -1.2634],
[ 1.9665, -0.6462, -0.0716, ..., -2.0842, 1.7766, -0.9148],
[ 0.9839, -0.6833, 0.2441, ..., -1.2677, 2.3247, -1.7913]]],
device='cuda:0', grad_fn=<NativeLayerNormBackward0>)
```
The model runs normally, with the 71 being due to the target (tgt) having the last token removed.
Model Training
For simplicity, we’re using the Adam optimizer for this model training, and no learning rate warmup is applied.
```python optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) ```
```python
class TranslationLoss(nn.Module):
def __init__(self):
super(TranslationLoss, self).__init__()
# Using KLDivLoss, no need to know the internal details.
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = 2
def forward(self, x, target):
"""
Forward pass of the loss function.
:param x: The output of the Decoder after passing through the predictor linear layer.
This is the state after the Linear layer and before the Softmax.
:param target: tgt_y, the label, for example [[1, 34, 15, ...], ...]
:return: loss
"""
"""
Since the input for KLDivLoss requires applying log to softmax, we use log_softmax.
Equivalent to: log(softmax(x))
"""
x = log_softmax(x, dim=-1)
"""
Construct the label distribution, which means converting [[1, 34, 15, ...]] into:
[[[0, 1, 0, ..., 0],
[0, ..., 1, .., 0],
...]],
...]
"""
# First, create a tensor full of zeros with the shape of x
true_dist = torch.zeros(x.size()).to(device)
# Set the corresponding index to 1
true_dist.scatter_(1, target.data.unsqueeze(1), 1)
# Identify <pad> indices, and set all corresponding values to 0 to prevent them from influencing the loss calculation.
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
# Calculate the loss
return self.criterion(x, true_dist.clone().detach())
```
```python criteria = TranslationLoss() ```
Once the loss function is defined, we can officially start training the model. The training process is not much different from regular model training. Here, I use TensorBoard to log the loss:
```python writer = SummaryWriter(log_dir='runs/transformer_loss') ```
You can start TensorBoard by running the command tensorboard --logdir runs in the current directory.
```python torch.cuda.empty_cache() ```
```python
step = 0
if model_checkpoint:
step = int('model_10000.pt'.replace("model_", "").replace(".pt", ""))
model.train()
for epoch in range(epochs):
loop = tqdm(enumerate(train_loader), total=len(train_loader))
for index, data in enumerate(train_loader):
# Generate data
src, tgt, tgt_y, n_tokens = data
src, tgt, tgt_y = src.to(device), tgt.to(device), tgt_y.to(device)
# Clear gradients
optimizer.zero_grad()
# Perform transformer calculations
out = model(src, tgt)
# Pass the results through the final linear layer for predictions
out = model.predictor(out)
"""
Calculate loss. Since we predict outputs for all tokens during training,
we need to reshape 'out'. The shape of 'out' is (batch_size, num_tokens, vocab_size),
and after view, it becomes (batch_size * num_tokens, vocab_size).
Among these predictions, we only need to focus on the non-<pad> tokens,
so we apply normalization, which means dividing by n_tokens.
"""
loss = criteria(out.contiguous().view(-1, out.size(-1)), tgt_y.contiguous().view(-1)) / n_tokens
# Compute gradients
loss.backward()
# Update parameters
optimizer.step()
loop.set_description("Epoch {}/{}".format(epoch, epochs))
loop.set_postfix(loss=loss.item())
loop.update(1)
step += 1
del src
del tgt
del tgt_y
if step != 0 and step % save_after_step == 0:
torch.save(model, model_dir / f"model_{step}.pt")
```
``` Epoch 0/10: 78%|███████▊ | 121671/156250 [9:17:29<2:37:46, 3.65it/s, loss=2.25] ```
Model Inference
After training the model, let’s use it to perform inference.
During inference with a Transformer, the target (tgt) is fed one token at a time to the Transformer. For example, initially, tgt is <bos>, and the prediction is I. Then, the second tgt is <bos> I, and the prediction is like. In the third step, tgt is <bos> I like, and so on, until the prediction is <eos>, or the maximum sentence length is reached.
```python model = model.eval() ```
```python
def translate(src: str):
"""
:param src: The English sentence, e.g., "I like machine learning."
:return: The translated sentence, e.g., "我喜欢机器学习"
"""
# Tokenize the source sentence and convert it into indices using the vocabulary, then add <bos> and <eos>
src = torch.tensor([0] + en_vocab(en_tokenizer(src)) + [1]).unsqueeze(0).to(device)
# Initially, the target is <bos>
tgt = torch.tensor([[0]]).to(device)
# Predict one word at a time until <eos> is predicted or the maximum sentence length is reached
for i in range(max_length):
# Perform the transformer computation
out = model(src, tgt)
# Since we only need the last word's prediction, we take `out[:, -1]`
predict = model.predictor(out[:, -1])
# Find the index of the maximum value
y = torch.argmax(predict, dim=1)
# Concatenate the predicted word with the previous predictions
tgt = torch.concat([tgt, y.unsqueeze(0)], dim=1)
# If <eos> is predicted, stop the loop
if y == 1:
break
# Join the predicted tokens and remove <s> and </s> tokens
tgt = ''.join(zh_vocab.lookup_tokens(tgt.squeeze().tolist())).replace("<s>", "").replace("</s>", "")
return tgt
```
```python
translate("Alright, this project is finished. Let's see how good this is.")
```
``` '好吧,这个项目完成了。让我们看看这是多好的。' ```

