【强化学习】 OpenAI Gym入门:基础组件(Getting Started With OpenAI Gym: The Basic Building Blocks)

本文说明
本文是对 OpenAI官方教程 中的“Getting Started With OpenAI Gym: The Basic Building Blocks”文章进行笔记精简总结,方便后续查询与复习。
虽然整体结构与官方文章一致,但内容并不一致,我按照我的思路进行了一定程度的修改。
学习本文需要对强化学习有一丢丢了解即可,主要是一些关键词。
这里也简单介绍和复习一下:
Environment: 可以理解为一个游戏。Observation:游戏运行过程中的某一个时刻的状态。例如某一帧游戏画面。Agent:被操控的游戏角色。例如在赛车中你的赛车就是Agent。Action:Agent可以做出的动作。分为离散和连续两种。例如:人物可以上下左右移动,这就是一个离散的动作,即从上下左右四种动作中选择一种Action。再比如,汽车的转向角度可以是0-90度的其中一个,甚至可以是小数,那么这就是一个连续的动作。reward:玩游戏时得到的奖励。例如吃到金币则加分,死亡则扣分。该值是用于训练AI的重要指标。AI的目标就是最大化reward
OpenAI Gym简介
OpenAI Gym是强化学习(Reinforcement Learning, RL)的一个库,其可以帮你方便的验证你的强化学习算法的性能,其中提供了许多Enviorment。目前是学术界公认的benchmark。
本文内容
- 安装
- Environments
- Spaces
- Wrappers
- Vectorized Environments
安装
直接使用pip安装即可(官方github地址):
```shell pip install -U gym ```
注意,仅支持Linux和MacOs, 官方不支持windows,但你可以找第三方的解决方案。 虽然官网这么说,但我测试下来发现windows可以直接安装。
本教程使用的是最新的 '0.25.1' 版本
gym提供了许多Environment,所以你可能还需要安装具体的Environment,例如本教程需要使用classic_control,所以还需要执行:
```shell pip install -U gym[classic_control] ```
Environments
Environment是Gym最核心的一个概念,一个Environment可以理解为一个游戏,例如:
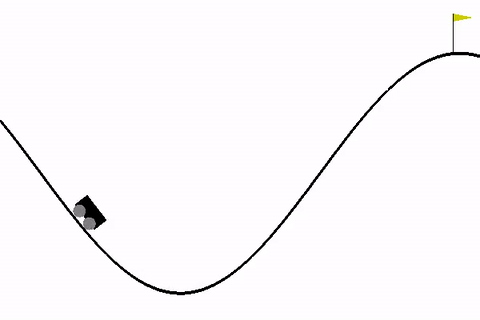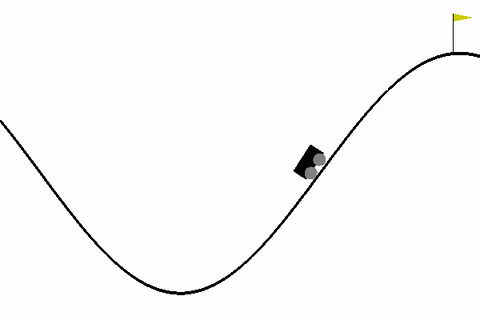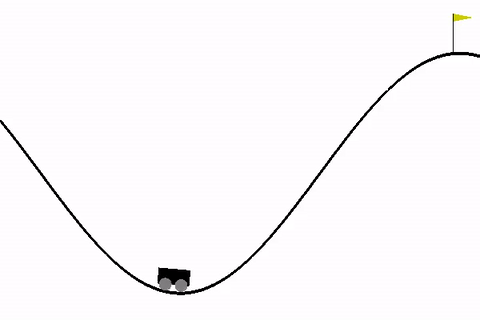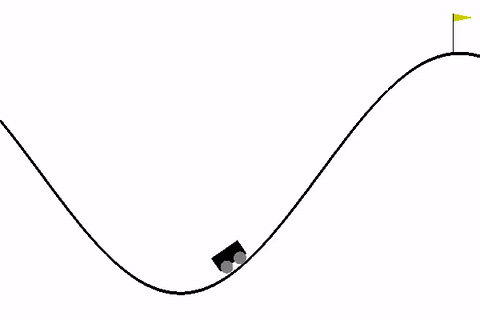
这个让小车到达山顶就是一个简单的游戏。你可以通过一个如下代码来加载该Environment:
```python
import gym
env = gym.make('MountainCar-v0')
```
其返回的是一个 Env 对象。OpenAI Gym提供了许多Environment可供选择:
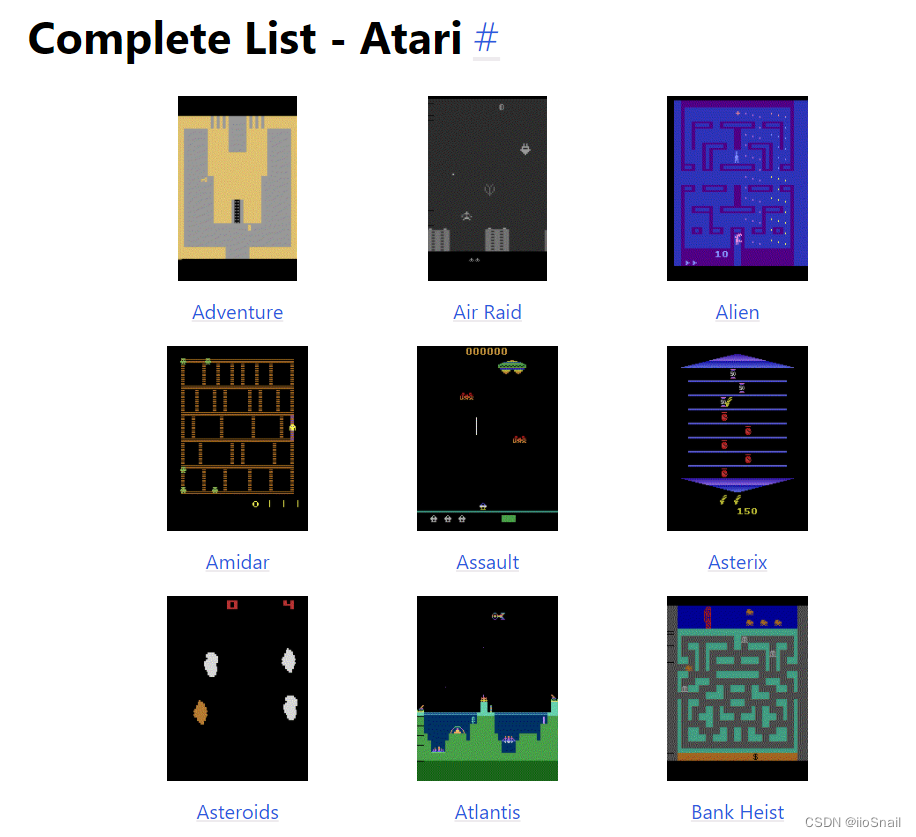
例如,上图是OpenAI Gym提供的雅达利游戏机的一些小游戏。你可以到官方寻找适合你的Environment来验证你的强化学习算法。
前面的小车游戏你可以在该地址找到,进入官方页面后,里面是对该Environment的描述:
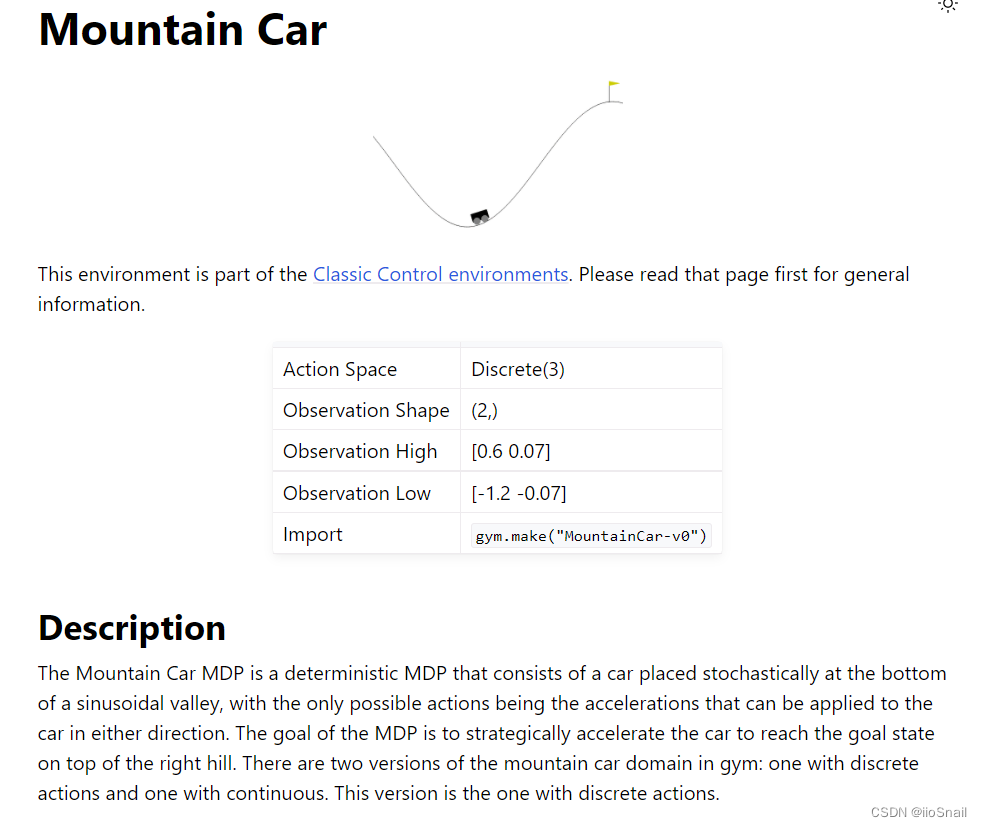
这其中最重要的就是表格中的内容,其主要包括两大部分:
- Action:Action就是Agent可以做出的动作,通常分为离散和连续两种。该表格中的
Discrete(3)表示该Agent可以做3中不同的动作。 - Observation:游戏Observation的状态。例如:Observation Shape为(2, ) 就表示该Environment的Observation是一个2维向量,其最大值分别为[0.6, 0.07],最小值分别为[-1.2, -0.07]
你也可以通过env对象的observation_space和action_space属性来查看上述内容:
```python print(env.observation_space) print(env.action_space) ```
``` 输出: Box([-1.2 -0.07], [0.6 0.07], (2,), float32) Discrete(3) ```
与Environment进行交互
与Environment进行交互换句话说就是打游戏。其主要通过调用env对象的函数来完成,其包含两个重要函数:
reset:重置环境,就是重置游戏。其会对环境进行状态初始化,并返回初始化后的observation。注意:虽然是重置,但也是初始化,也就是env即使是第一次使用也要调用resetstep:采取行动。就是让Agent采取一个动作,例如向前移动。step函数返回做完该动作后的信息,包括以下4个返回值:observation:执行该动作后的游戏状态reward:执行该动作后得到的reward。done:游戏是否终止。例如命都用完了,则游戏终止,done=Trueinfo:一些额外的信息,例如还剩几条命等。不同的游戏info不同
代码演示:
```python
# 重置环境,虽说是重置,第一次使用env前,也要调用
# reset会返回初始的observation
observation = env.reset()
print("The initial observation is {}".format(observation))
# 从动作中随机选择一个,random_actio
random_action = env.action_space.sample()
print("The random action is {}".format(random_action))
# 调用step,执行上述的动作,得到下一个状态
new_obs, reward, done, info = env.step(random_action)
print("The new observation is {}".format(new_obs))
print("The reward is {}".format(reward))
```
``` 输出: The initial observation is [-0.5330634 0. ] The random action is 0 The new observation is [-0.41475227 -0.0018148 ] The reward is -1.0 ```
看这种干巴巴的数字没意思,可以通过render方法渲染成图片:
```python import matplotlib.pyplot as plt env_screen = env.render(mode = 'rgb_array') plt.imshow(env_screen) ```
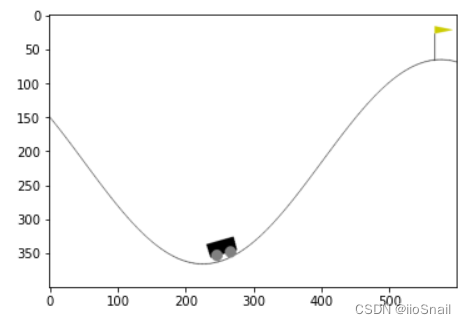
我们来看一个更完整的例子:
```python
import time
# 初始化环境
obs = env.reset()
# 让Agent进行1500次动作
for step in range(1500):
# 选择一个随机的动作,这里可以替换成你训练好的智能算法
action = env.action_space.sample()
# 采取行动,然后得到下个状态
obs, reward, done, info = env.step(action)
# 如果游戏结束,则跳出循环
if done:
break
# 关闭env
env.close()
```
你可以依据你的具体环境(Jupyter, Py等)来在上面的代码中使用env.render来增加实时动画,例如如果使用Google Colab,则你可以使用以下代码来显示动画:
```shell !apt install xvfb ```
```shell !pip install pyvirtualdisplay ```
```python %%capture from pyvirtualdisplay import Display virtual_display = Display(visible=0, size=(1400, 900)) virtual_display.start() %matplotlib inline import matplotlib.pyplot as plt from IPython import display ```
```python
import time
import gym
env = gym.make('MountainCar-v0')
# 初始化环境
obs = env.reset()
img = plt.imshow(env.render(mode='rgb_array'))
# 让Agent进行1500次动作
for step in range(1500):
# 选择一个随机的动作,这里可以替换成你训练好的智能算法
action = env.action_space.sample()
# 采取行动,然后得到下个状态
obs, reward, done, info = env.step(action)
img.set_data(env.render(mode='rgb_array'))
display.display(plt.gcf())
display.clear_output(wait=True)
# 如果游戏结束,则跳出循环
if done:
break
# 关闭env
env.close()
```
Spaces
上一节我们提到每个Environment的文档中都会有一个表格:

这个表格就是Space,它里面记录了这个环境的Observation和Action的合法值。例如Action Space是3个离散值,通常为0,1,2,如果此时你使用env.step(3),那就会报错,因为3不是一个合法的Action。
我们可以通过env.observation_space获取到observation的space,其返回一个Box的对象,里面记录了Observation的Shape、High(最大值)、Low(最小值)等信息。这些我们上一节都讲过了。这节就不再赘述了
Wrapper
有时候官方提供的observation和reward等不满足你的需求,那么你可以使用包装类来自定义你的需求。
这里直接上例子。假设我们现在要训练AI玩打砖块游戏:
官方提供对该游戏的observation的Shape为(210, 160, 3),也就是一帧图片:
```python
env = gym.make("BreakoutNoFrameskip-v4")
print("Observation Space: ", env.observation_space)
print("Action Space ", env.action_space)
```
``` 输出: Observation Space: Box(210, 160, 3) Action Space Discrete(4) ```
但为了训练处更好的AI,用一帧图片来决定木板应该如何移动不太够,最好可以有前几帧的画面,所以我们希望Observation的Shape为(4, 210, 160, 3),其中4代表前4帧的图片。使用包装类,我们可以这么做:
```python
from collections import deque
from gym import spaces
import numpy as np
class ConcatObs(gym.Wrapper):
def __init__(self, env, k):
gym.Wrapper.__init__(self, env)
self.k = k
self.frames = deque([], maxlen=k)
shp = env.observation_space.shape
self.observation_space = \
spaces.Box(low=0, high=255, shape=((k,) + shp), dtype=env.observation_space.dtype)
def reset(self):
ob = self.env.reset()
for _ in range(self.k):
self.frames.append(ob)
return self._get_ob()
def step(self, action):
ob, reward, done, info = self.env.step(action)
self.frames.append(ob)
return self._get_ob(), reward, done, info
def _get_ob(self):
return np.array(self.frames)
```
```python
env = gym.make("BreakoutNoFrameskip-v4")
wrapped_env = ConcatObs(env, 4)
print("The new observation space is", wrapped_env.observation_space)
```
``` 输出: The new observation space is Box(4, 210, 160, 3) ```
OpenAI Gym对Observation、Reward和Action也都提供了Wrapper类:
```python
import random
class ObservationWrapper(gym.ObservationWrapper):
def __init__(self, env):
super().__init__(env)
def observation(self, obs):
# Normalise observation by 255
return obs / 255.0
class RewardWrapper(gym.RewardWrapper):
def __init__(self, env):
super().__init__(env)
def reward(self, reward):
# Clip reward between 0 to 1
return np.clip(reward, 0, 1)
class ActionWrapper(gym.ActionWrapper):
def __init__(self, env):
super().__init__(env)
def action(self, action):
if action == 3:
return random.choice([0,1,2])
else:
return action
```
```python
env = gym.make("BreakoutNoFrameskip-v4")
wrapped_env = ObservationWrapper(RewardWrapper(ActionWrapper(env)))
obs = wrapped_env.reset()
for step in range(500):
action = wrapped_env.action_space.sample()
obs, reward, done, info = wrapped_env.step(action)
# Raise a flag if values have not been vectorised properly
if (obs > 1.0).any() or (obs < 0.0).any():
print("Max and min value of observations out of range")
# Raise a flag if reward has not been clipped.
if reward < 0.0 or reward > 1.0:
assert False, "Reward out of bounds"
# Check the rendering if the slider moves to the left.
wrapped_env.render()
time.sleep(0.001)
wrapped_env.close()
print("All checks passed")
```
Vectorized Environments
该模块是关于强化学习并行计算的,个人认为是非入门部分,暂不学习。如果感兴趣,可以去官网看。