Digital Human Project ER-NeRF: A Detailed Guide for Use and Deployment

Table of Content
1. Introduction to ER-NeRF
ER-NeRF (Official Github) is a Talking Portrait Synthesis project. In brief, given a video of someone speaking and an audio clip, this model processes the video to make the speaker’s lip movements match the audio.
Advantages of this model include:
- Real-time response: The model is lightweight and processes quickly.
Disadvantages:
- Every video used for lip-syncing requires training. In other words, each video corresponds to a unique model.
- The generated head movements are not very stable.
2. Deploying ER-NeRF
Environment requirements for ER-NeRF:
- PyTorch 1.12
- CUDA 11.x (mandatory, or there will be errors with the PyTorch3D-related code)
Deployment steps::
(1). Run the following commands in order (execute one by one):
```python # The local CUDA version doesn't have to be exactly 11.6, but it must be 11.x. conda install cudatoolkit=11.6 -c pytorch # Install PyTorch pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --index-url https://download.pytorch.org/whl/cu116 # Install PyTorch3D. This step must succeed, or errors will occur in the later data processing stages pip install "git+https://github.com/facebookresearch/pytorch3d.git" # Install TensorFlow pip install tensorflow-gpu==2.8.0 # Install necessary libraries apt-get update apt install portaudio19-dev apt-get install ffmpeg # Clone the project repository git clone https://github.com/Fictionarry/ER-NeRF.git # Install the required libraries cd ER-NeRF pip install -r requirements.txt # Reinstall protobuf and use version 3.20.3 pip uninstall protobuf pip install protobuf==3.20.3 ```
(2). Download the model files from the link given by the project. After finishing it, the structure should look like this:
```
-- checkpoints # Place this in the `~/.cache/torch/hub/checkpoints` directory (optional, as the source code can download it automatically)
-- data_utils # Place this in the '`ER-NeRF/data_utils` directory'
-- face_parsing
-- face_tracking
```
(3). Initialize 3DMM model-related files:
```python cd data_utils/face_tracking python convert_BFM.py ```
3. Training Your Own Digital Human
If you just want to use an existing model (currently only Obama), you can skip to Chapter 4.
The source code includes a pre-trained video (Obama). If you want to train your own digital human model, follow these steps (using the provided Obama video as an example):
(1). Download the video you want to train on and place it in the data directory. Name the video as data/<ID>/<ID>.mp4. For example, kunkun.mp4 would be placed in ER-NeRF/data/kunkun/kunkun.mp4.
```python wget https://github.com/YudongGuo/AD-NeRF/blob/master/dataset/vids/Obama.mp4?raw=true -O data/obama/obama.mp4 ```
Video requirements (must be met): ① Frame rate: 25FPS; ② Every frame should show the person speaking; ③ Resolution: 512x512; ④ Duration: 1-5 minutes; ⑤ The background should remain stable. Tip: You can use "Leawo Video Converter Ultimate" to process the video.
(2). Process the video using the data_utils/process.py script.
```python python data_utils/process.py data/<ID>/<ID>.mp4 ```
This step will take some time and is error-prone (often due to incorrect environment setup). The script process.py contains multiple tasks, each generating several files saved in the data/<ID>/* folder. You can check if each task completed successfully by looking for the generated files or checking the logs:
- Task 1: Splitting the video. This task generates the
aud.wavfile. If it fails, it's usually caused byffmpeg. You can try to reinstall it to resolve problems. - Task 2: Extract audio data (
aud.npy) . Errors here are typically due toprotobufversion problems. - Task 3: Extracting each frame from the video. This task will generate many image files like
ori_imgs/XXX.jpg. - Task 4: Semantic segmentation. This task generates many
parsing/XX.pngfiles. - Task 5: Extracting the background image, generating a
bc.jpgfile (background image of the person). - Task 6: Segmenting body parts and creating Ground Truth images, generating
gt_imgs/XXX.jpgandtorso_imgs/XXX.png(torso-only images without the face). - Task 7: Extracting facial landmark coordinates, generating
ori_imgs/XXX.lmsfiles. - Task 8: Generating face tracking data by training a tracking model (this task will take a long time). This task generates the
track_params.ptfile. Errors here are often related topytorch3dorCUDAversion. - Task 9: Generating
transformers_train.jsonandtransforms_val.json.
If a task fails, you can retry it using the command:
python data_utils/process.py data/<ID>/<ID>.mp4 --task <taskId>. For example, to retry task 2:python data_utils/process.py data/obama/obama.mp4 --task 2
(3). Make a copy of the generated aud.npy file and rename it to aud_ds.npy (There are some bugs in the source code, so you should take this step).
(4). Generate the <ID>.csv file using OpenFace. The specific steps are as follows: ① Download OpenFace (link for windows version) ;② Extract the files and run OpenFaceOffline.exe; ③ In the Record tab, only check Record AUs.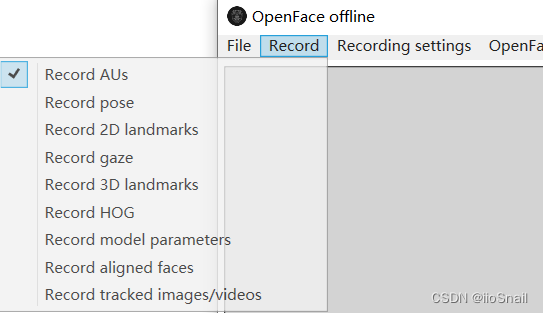
;④ Select File->Open Video, then the process will start;⑤ After it finishes, a <ID>.csv file will be generated in the ./processed folder. Rename it to au.csv and place it in the data/<ID>/ folder.
(5). Train the model by running the following commands:
```python # Command 1: Train the model python main.py data/obama/ --workspace trial_obama/ -O --iters 100000 # Command 2: Fine-tune python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32 ```
trial_obama is the workspace where the generated model will be saved. After running the commands, a trial_obama folder will be created with the following structure:
```
-- checkpoints/ # Model files
├── ngp_ep0013.pth # Model for the 13th epoch
├── ngp_ep0014.pth
└── ngp.pth # Final model file
-- log_ngp.txt # Log file
-- opt.txt # Training options (args).
-- result # Result files
├── ngp_ep0014_depth.mp4
└── ngp_ep0014.mp4 # You can download and check the result.
-- run/ngp/events.out.xxxxx
-- validation
```
After completing the above commands, run the following:
```python python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt trial_obama/checkpoints/ngp.pth --iters 200000 ```
trial_obama/checkpoints/ngp.pth is the final model file generated earlier.
4. Generating Digital Human Videos
Once the model is generated, you can use your own voice to create videos. Follow these three steps:
(1). Upload the audio and extract audio data (generate the corresponding npy file).
For example:
```python python data_utils/deepspeech_features/extract_ds_features.py --input /root/demo2.wav ```
Change
demo2.wavto your audio file. After execution, ademo2.npyfile will be generated in the same directory.
(2). Run the model inference to generate the lip-synced video file. Note that the generated video will have no audio.
```python python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud /root/demo2.npy ```
(3). Merge the audio and video together.
```python ffmpeg -i /root/ER-NeRF/trial_obama_torso/results/ngp_ep0028.mp4 -i /root/demo2.wav -c:v copy -c:a aac -strict experimental /root/output.mp4 ```
ngp_ep0028.mp4is the video generated in the second step (you can find its location in the log file). Thedemo2.wavis the uploaded audio and/root/output.mp4is the path for the output file you want.
5. Comparison of Other Digital Human Models
| Model Name | Inference Speed | Require Training | Advantages | Disadvantages |
|---|---|---|---|---|
| video-retalking | Slow | Not | 1. Simple deployment 2.No training needed; can be used directly on any video 3.Mature project with strong compatibility 4. Includes video processing, no need for video processing by yourself |
1. Slow inference speed, not capable of real-time processing. 2.Unstable results; some videos have poor performance |
| ER-NeRF | Fast | Required | 1. Small model, fast inference speed, meets real-time requirements 2. Good lip-syncing effect |
1. Immature project; it's source code from a paper. 2. Poor compatibility, strict requirements for the deployment environment. 3. Data processing and training are time-consuming; a 5-minute video takes about one day. |
| Wav2Lip | Fast | Not | 1. Mature project |
1. Project is quite old (4 years ago). 2. Low resolution. |
FAQ
Common Errors
ValueError: Found array with 0 sample(s) (shape=(0, 2)) while a minimum of 1 is required by NearestNeighbors.:
```python
Traceback (most recent call last):
File "data_utils/process.py", line 417, in <module>
extract_background(base_dir, ori_imgs_dir)
File "data_utils/process.py", line 112, in extract_background
nbrs = NearestNeighbors(n_neighbors=1, algorithm='kd_tree').fit(fg_xys)
File "/root/miniconda3/lib/python3.8/site-packages/sklearn/base.py", line 1152, in wrapper
return fit_method(estimator, *args, **kwargs)
File "/root/miniconda3/lib/python3.8/site-packages/sklearn/neighbors/_unsupervised.py", line 175, in fit
return self._fit(X)
File "/root/miniconda3/lib/python3.8/site-packages/sklearn/neighbors/_base.py", line 498, in _fit
X = self._validate_data(X, accept_sparse="csr", order="C")
File "/root/miniconda3/lib/python3.8/site-packages/sklearn/base.py", line 605, in _validate_data
out = check_array(X, input_name="X", **check_params)
File "/root/miniconda3/lib/python3.8/site-packages/sklearn/utils/validation.py", line 967, in check_array
raise ValueError(
ValueError: Found array with 0 sample(s) (shape=(0, 2)) while a minimum of 1 is required by NearestNeighbors.
```
Cause: Some frames in the video do not contain any faces. This typically occurs at the beginning or end of the video. You can confirm this by checking the images in the generated parsing folder. See details in the issue
RuntimeError: Given groups=1, weight of size [32, 44, 3], expected input[8, 29, 16] to have 44 channels, but got 29 channels instead
```python
==> Start Training Epoch 1, lr=0.001000 ...
0% 0/7355 [00:00<?, ?it/s]Traceback (most recent call last):
File "main.py", line 248, in <module>
trainer.train(train_loader, valid_loader, max_epochs)
File "/root/ER-NeRF/nerf_triplane/utils.py", line 983, in train
self.train_one_epoch(train_loader)
File "/root/ER-NeRF/nerf_triplane/utils.py", line 1241, in train_one_epoch
self.model.update_extra_state()
File "/root/miniconda3/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/root/ER-NeRF/nerf_triplane/renderer.py", line 432, in update_extra_state
enc_a = self.encode_audio(auds)
File "/root/ER-NeRF/nerf_triplane/network.py", line 232, in encode_audio
enc_a = self.audio_net(a) # [1/8, 64]
File "/root/miniconda3/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/root/ER-NeRF/nerf_triplane/network.py", line 64, in forward
x = self.encoder_conv(x).squeeze(-1)
File "/root/miniconda3/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/root/miniconda3/lib/python3.8/site-packages/torch/nn/modules/container.py", line 139, in forward
input = module(input)
File "/root/miniconda3/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/root/miniconda3/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 307, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/root/miniconda3/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 303, in _conv_forward
return F.conv1d(input, weight, bias, self.stride,
RuntimeError: Given groups=1, weight of size [32, 44, 3], expected input[8, 29, 16] to have 44 channels, but got 29 channels instead
```
Cause: It usually happens when you want to use the Wav2vec audio extractor, but the --asr wav2vec parameter was forgotten.
python: can't open file 'nerf/asr.py': [Errno 2] No such file or directory
```python [INFO] ===== extract audio labels for data/zhf/aud.wav ===== python: can't open file 'nerf/asr.py': [Errno 2] No such file or directory [INFO] ===== extracted audio labels ===== ```
Cause: There is an issue in the source code that needs to be rewritten. See issues#91
How to Process a Video?
Note: My knowledge of audio and video processing is lacking, so my approach may not be optimal. Here are my steps:
- Download the “Leawo Video Converter Ultimate” software and open the video you need to process.
- Use the "Cut" option to select "Start Time" and "End Time."
- Use the "Crop" option to set the size to "Square" and select "Full Screen." You might notice that the video is stretched or squished, which is normal due to display aspect ratio is not correct.
- Click Convert to generate the video.
- Use ffmpeg to process the video to 512x512, using the command:
ffmpeg -i input.mp4 -vf scale=512:512 output.mp4 - Use ffmpeg to set the aspect ratio of the video to 512:512 (1:1) with the command:
ffmpeg -i input.mp4 -aspect 512:512 output.mp4
If you need to rotate your video, you can use the command:
ffmpeg -i input.mp4 -vf "transpose=2" output.mp4
Inference Acceleration (Using wav2vec)
Using the default DeepSpeech to extract audio features can be slow. You can choose to use wav2vec for audio feature extraction, which will significantly speed up inference.
You need to add some parameters during both the training and inference phases to select the use of wav2vec:
Training Phase:
- In Step 2, add the --asr wav2vec parameter:
python data_utils/process.py data/<ID>/<ID>.mp4 --asr wav2vec - Change
aud_ds.npyin Step 3 toaud_eo.npy, meaning you should copy the generatedaud.npyand rename it toaud_eo.npy. - Add the
--asr_model esperantoparameter in Step 5:
```python python main.py data/obama/ --workspace trial_obama/ -O --iters 100000 --asr_model esperanto python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32 --asr_model esperanto python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt trial_obama/checkpoints/ngp.pth --iters 200000 --asr_model esperanto ```
Inference Phase:
- For audio processing in Step 1, use
wav2vec.py, with the command:python data_utils/wav2vec.py --wav /root/demo2.wav --save_feats - In Step 2, add the
--asr_model esperantoparameter with the command:python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud /root/demo2_eo.npy --asr_model esperanto

